Code
!pip install dldna[colab] # in Colab
# !pip install dldna[all] # in your local
%load_ext autoreload
%autoreload 2 ![]()
“La eficiencia es el puente hacia la inteligencia.” - Alan Turing
Desde la aparición de los Transformers en 2017, han surgido sucesivamente modelos de lenguaje grandes representados por BERT y GPT. Estos modelos han abierto una nueva era en la inteligencia artificial con sus sorprendentes rendimientos. Sin embargo, detrás de este éxito se encontraban las limitaciones fundamentales de la arquitectura de los Transformers y los esfuerzos para superarlas. Se realizaron mejoras constantes y propuestas estructurales para superar problemas de complejidad computacional y limitaciones en el procesamiento de textos largos. En particular, desde 2019, con el rápido aumento del tamaño de los modelos, se ha intensificado la investigación sobre eficiencia.
Cambios principales por período:
En este capítulo examinaremos las limitaciones de los Transformers y detallaremos diversas soluciones para superarlas.
Desafío: ¿Cómo reducir la complejidad computacional y el uso de memoria del modelo Transformer, procesar contextos más largos y entrenar modelos más grandes?
Angustia del investigador: Aunque el rendimiento de los modelos Transformer era sobresaliente, su costo computacional era enorme. En particular, el mecanismo de atención tenía una complejidad proporcional al cuadrado de la longitud de la secuencia, lo que limitaba severamente la escalabilidad del modelo. Los investigadores tenían que encontrar formas de aumentar la eficiencia computacional mientras mantenían las funciones esenciales de la atención. No se trataba simplemente de reducir el tamaño del modelo, sino de buscar soluciones innovadoras a nivel de algoritmos y hardware. Esto era un desafío similar a construir un edificio enorme mientras se reducía el peso y el costo de cada ladrillo.
La complejidad cuadrática de la operación de atención, las longitudes limitadas de contexto y los problemas de eficiencia en memoria fueron los principales obstáculos para la expansión del modelo. Estas limitaciones se convirtieron en factores cruciales que determinaron la dirección del desarrollo de los Transformers.
Durante el proceso de escalado de modelos Transformer, la complejidad de las operaciones de atención, particularmente la proporcional a la longitud cuadrática de la secuencia, fue un gran problema.
Análisis de la complejidad de la operación de atención:
\(Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}})V\)
Vamos a ver esto en código para observar la velocidad de ejecución y el uso de memoria.
!pip install dldna[colab] # in Colab
# !pip install dldna[all] # in your local
%load_ext autoreload
%autoreload 2from dldna.chapter_09.complexity_benchmark import measure_attention_complexity, plot_complexity_analysis, measure_attention_complexity_gpu
seq_lengths = [100, 500, 1000, 2000, 4000, 8000, 10000, 15000]
results = measure_attention_complexity(seq_lengths=seq_lengths)
print("\n=== Complexity Analysis of Attention Operation ===")
print("\nMemory usage and execution time by sequence length:")
print("Length\t\tMemory (MB)\tTime (seconds)")
print("-" * 40)
for seq_len, mem, time_taken in results:
print(f"{seq_len}\t\t{mem:.2f}\t\t{time_taken:.4f}")
# Visualize with a graph
plot_complexity_analysis(results)
=== Complexity Analysis of Attention Operation ===
Memory usage and execution time by sequence length:
Length Memory (MB) Time (seconds)
----------------------------------------
100 18.75 0.0037
500 96.58 0.0388
1000 317.00 0.1187
2000 1119.00 0.4228
4000 4188.14 1.6553
8000 16142.53 6.5773
10000 25039.31 10.2601
15000 55868.54 25.1265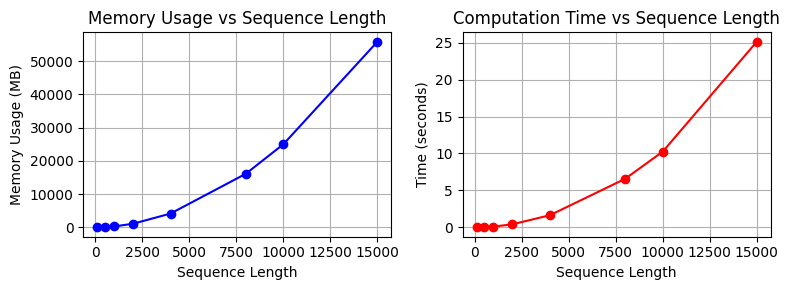
En los modelos de transformador reales, esta operación se repite a través de múltiples capas. El aumento del tamaño del lote también aumenta la cantidad de cálculos.
# Compare theoretical complexity with actual measurements
print("\n=== Comparison of Theoretical Complexity and Actual Measurements ===")
base_seq = seq_lengths[0]
base_mem = results[0][1]
base_time = results[0][2]
print("\nTheoretical vs Actual Growth Rate (Base: First Sequence Length)")
print("Length Theoretical(N²) Actual Memory Actual Time")
print("-" * 60)
for seq_len, mem, time_taken in results:
theoretical = (seq_len/base_seq) ** 2
actual_mem = mem/base_mem
actual_time = time_taken/base_time
print(f"{seq_len:6d} {theoretical:10.2f}x {actual_mem:10.2f}x {actual_time:10.2f}x")
=== Comparison of Theoretical Complexity and Actual Measurements ===
Theoretical vs Actual Growth Rate (Base: First Sequence Length)
Length Theoretical(N²) Actual Memory Actual Time
------------------------------------------------------------
100 1.00x 1.00x 1.00x
500 25.00x 5.15x 8.05x
1000 100.00x 16.91x 32.49x
2000 400.00x 59.71x 124.52x
4000 1600.00x 223.34x 474.71x
8000 6400.00x 860.92x 1882.04x
10000 10000.00x 1335.43x 2976.84x
15000 22500.00x 2979.67x 7280.40xLa complejidad cuadrática es particularmente grave en modelos a gran escala como GPT-3. Esto ha llevado a numerosas limitaciones, como la restricción de procesamiento de documentos largos y el límite de tamaño de lote durante el entrenamiento. Esta situación se convirtió en un motivo principal para desarrollar mecanismos de atención más eficientes.
Los primeros intentos para abordar el problema de complejidad cuadrática en los transformadores tomaron principalmente tres direcciones.
Atención con ventana deslizante
Calcula la atención solo dentro de una ventana de tamaño fijo.
def sliding_window_attention(q, k, v, window_size):
"""Sliding window attention"""
batch_size, seq_len, dim = q.shape
attention_weights = np.zeros((batch_size, seq_len, seq_len))
for i in range(seq_len):
start = max(0, i - window_size // 2)
end = min(seq_len, i + window_size // 2 + 1)
scores = np.matmul(q[:, i:i+1], k[:, start:end].transpose(0, 2, 1))
attention_weights[:, i, start:end] = softmax(scores, axis=-1)
return np.matmul(attention_weights, v)Este método reduce la complejidad a \(O(N \cdot w)\) (w: tamaño de la ventana).
Patrón de atención dispersa
El patrón de atención dispersa es un enfoque que, en lugar de calcular las relaciones entre todas las parejas de tokens, solo calcula algunas relaciones según ciertos patrones. Por ejemplo, si tenemos una secuencia compuesta por 10 tokens, la atención normal calcularía 100 (10×10) relaciones, pero la atención dispersa solo calculará un subconjunto de estas.
def sparse_block_attention(q, k, v, block_size):
"""Block sparse attention
Example: seq_len=8, block_size=2
Process the sequence in 4 blocks of 2 tokens each
Block 1 (0,1), Block 2 (2,3), Block 3 (4,5), Block 4 (6,7)
"""
batch_size, seq_len, dim = q.shape # e.g., (1, 8, 64)
num_blocks = seq_len // block_size # e.g., 8/2 = 4 blocks
attention_weights = np.zeros((batch_size, seq_len, seq_len))
for i in range(num_blocks):
# e.g., when i=0, process Block 1 (0,1)
start_q = i * block_size # 0
end_q = (i + 1) * block_size # 2
for j in range(num_blocks):
# e.g., when j=0, attention with Block 1 (0,1)
start_k = j * block_size # 0
end_k = (j + 1) * block_size # 2
# Calculate attention between tokens in Block 1 (0,1) and Block 1 tokens (0,1)
scores = np.matmul(
q[:, start_q:end_q], # (1, 2, 64)
k[:, start_k:end_k].transpose(0, 2, 1) # (1, 64, 2)
) # Result: (1, 2, 2)
# Store weights block by block
attention_weights[:, start_q:end_q, start_k:end_k] = softmax(scores, axis=-1)
# Generate the final context vectors
return np.matmul(attention_weights, v)Aproximación de rango bajo
La aproximación de rango bajo es una técnica que representa matrices grandes como el producto de matrices más pequeñas. Por ejemplo, en una oración con 10 tokens, la atención general calcula 10×10=100 relaciones, mientras que la aproximación de rango bajo las representa como el producto de dos matrices de 10×4 y 4×10 (rango=4). De esta manera, se obtienen resultados similares con solo 80 operaciones en lugar de 100.
def low_rank_attention(q, k, v, rank):
"""Low-rank attention
Example: seq_len=10, dim=64, rank=16
Project Q, K from 64 dimensions to 16 dimensions to reduce computation
"""
batch_size, seq_len, dim = q.shape # e.g., (1, 10, 64)
# Create projection matrices to project from 64 dimensions to 16 dimensions
projection_q = np.random.randn(dim, rank) / np.sqrt(rank) # (64, 16)
projection_k = np.random.randn(dim, rank) / np.sqrt(rank)
# Project Q, K to 16 dimensions
q_low = np.matmul(q, projection_q) # (1, 10, 16)
k_low = np.matmul(k, projection_k) # (1, 10, 16)
# Calculate attention in the lower dimension (operations on 10x16 matrices)
attention = np.matmul(q_low, k_low.transpose(0, 2, 1)) # (1, 10, 10)
attention_weights = softmax(attention, axis=-1)
# Generate the final context vectors
return np.matmul(attention_weights, v) # (1, 10, 64)Este método puede reducir la complejidad a \(O(N \cdot r)\). Aquí, \(r\) es el rango utilizado en la aproximación. Vamos a calcular la eficiencia de cada método.
from dldna.chapter_09.attention_complexity_examples import calcualte_efficieny
calcualte_efficieny()Original input shape: (2, 8, 4)
1. Sliding Window Attention
Output shape: (2, 8, 4)
Output of the first batch, first token: [-0.78236164 0.22592055 -1.03027549 1.13998368]
2. Block Sparse Attention
Output shape: (2, 8, 4)
Output of the first batch, first token: [-1.66095776 0.76700744 -0.45857165 -0.77422867]
3. Low-Rank Attention
Output shape: (2, 8, 4)
Output of the first batch, first token: [ 0.51121005 0.66772692 -0.77623488 -0.0323534 ]
Memory Usage Comparison (Relative Size):
Full Attention: 64
Sliding Window: 32
Block Sparse: 64
Low Rank: 32Sin embargo, los primeros intentos mostraron limitaciones como la pérdida de información, la complejidad de implementación y el deterioro del rendimiento. Google se enfocó en la aproximación de rango bajo, mientras que Microsoft centró sus esfuerzos en el desarrollo de patrones dispersos. Posteriormente, estos enfoques iniciales evolucionaron hacia un método híbrido que aprovecha tanto la dispersidad como las características de rango bajo.
Otra limitación importante es la eficiencia de memoria. Particularmente en modelos de lenguaje a gran escala, existen las siguientes cargas de memoria.
En primer lugar, la carga de memoria causada por el caché KV (Key-Value). Durante el proceso de generación autoregresiva, se deben almacenar los valores de Key y Value de los pasos temporales anteriores, lo cual aumenta linealmente con la longitud de la secuencia. Por ejemplo, en el caso de GPT-3, al procesar 2048 tokens, se requiere aproximadamente 16MB de caché KV por cada capa. En segundo lugar, los requisitos de memoria del proceso de retropropagación. El transformer almacena los valores de activación intermedios (activation value) - los resultados de cálculos intermedios que ocurren en la capa de atención (valores transformados Q, K, V, scores de atención, salidas softmax, etc.) - lo cual aumenta drásticamente a medida que se incrementa el número de capas. En el caso de BERT-large, incluso con un solo lote, se requerían aproximadamente 24GB de memoria. En tercer lugar, el uso de memoria por las operaciones de atención en sí mismas. La matriz de scores de atención tiene un tamaño proporcional al cuadrado de la longitud de la secuencia, lo que puede ser un cuello de botella grave al procesar documentos largos.
Para abordar estos problemas de memoria, se han propuesto técnicas de optimización como el checkpointing de gradientes, el entrenamiento con precisión mixta y FlashAttention.
Para superar las limitaciones de complejidad computacional y eficiencia de memoria discutidas en las secciones 9.1.1 y 9.1.2, los investigadores han desarrollado diversas técnicas para mejorar la eficiencia y escalabilidad. Estas técnicas han hecho que los modelos transformer sean más potentes y prácticos, y han tenido un gran impacto en el campo del aprendizaje profundo.
En este capítulo, presentamos un resumen de las tendencias temporales en el desarrollo del transformer, introduciendo las principales tecnologías y modelos de cada período, como se muestra en la siguiente tabla.
Tabla: Tendencias temporales en el desarrollo del transformer, modelos/técnicas clave, contenido principal, ADN del aprendizaje profundo | Sección | Período (aproximado) | Principales modelos/técnicas | Contenido y explicación clave | ADN del aprendizaje profundo | |———–|———————–|————————————|————————————–|———————————–| | 9.1 | 2017-2018 | Transformer | Introducción de un mecanismo de Attention para superar las limitaciones de los RNN y CNN tradicionales.
Innovación en modelos sequence-to-sequence | Mecanismo de Attention: Proporciona una nueva forma de enfocarse en partes importantes de los datos | | 9.2 | 2019-2020 | Performer, Sparse Transformer, Longformer
Reformer, BigBird | Enfoque de software para reducir la complejidad computacional.
Atención lineal: Aproximación del cálculo de atención (Performer).
Atención dispersa: Aplicación de atención solo a ciertas pares de tokens (Sparse Transformer, Longformer).
Atención local-global: Combinación de información local y global (Reformer, BigBird) | Atención eficiente: Esfuerzos para mantener las ventajas de la atención mientras se reduce la complejidad computacional.
Dependencias a larga distancia: Mejoras en la estructura para manejar contextos largos efectivamente | | 9.3 | 2021-2022 | FlashAttention, MQA, GQA, PagedAttention, vLLM | Enfoques de hardware y software para mejorar la eficiencia en memoria.
FlashAttention: Uso de la jerarquía de memoria GPU, tiling, procesamiento por bloques.
MQA/GQA: Optimización de consultas, compartición Key/Value.
Optimización del caché KV: PagedAttention, vLLM | Optimización de hardware: Métodos eficientes de cálculo considerando la estructura de memoria GPU.
Procesamiento paralelo: Aumento de la eficiencia en el procesamiento a través de compartición de consultas | | 9.4 | 2022-2023 | Claude-2, LongLoRA, Constitutional AI, RLHF,
RLAIF, Atención jerárquica, Memoria recurrente | Arquitecturas para la escalabilidad y fines específicos.
Contexto largo: Atención jerárquica, Transformador de memoria recurrente.
Ética/seguridad: Atención basada en reglas, ajustes basados en aprendizaje por refuerzo | Contexto largo: Evolución de la estructura del modelo para manejar contextos más largos.
Ajuste fino: Métodos para ajustar el modelo a fines específicos | | 9.5 | 2022-2023 | Codificador eficiente (basado en FlashAttention) | Clasificación de texto (AG News), FlashAttention, Pre-LN, Gradient Checkpointing, Entrenamiento con precisión mixta | Implementación: Uso de un codificador eficiente | | 9.6 | 2023 | Mistral, Decodificador eficiente (basado en GQA y Atención de ventana deslizante) | Análisis del modelo Mistral: GQA, Atención de ventana deslizante, RoPE, caché KV.
Ejemplos de aplicación: Conversión número-texto, conversión de lenguaje natural-SQL (generación de código), generación de texto-código. | Implementación: Arquitectura de decodificador eficiente | | 9.7 | 2024 | Gemma | Modelo abierto para mejorar la eficiencia y el acceso | Modelo abierto: Mejora del acceso a la investigación y al desarrollo | | 9.8 | 2024 | Phi-3 | LLM pequeño pero eficiente | Implementación: Potente SLM (Small Language Model) | La estructura de este capítulo es la siguiente:
Desde 2019 hasta 2020, se realizaron varios intentos para reducir la complejidad computacional de los transformers. Particularmente, el desarrollo durante este período liderado por Google Research y DeepMind mejoró significativamente la eficiencia de las operaciones de atención.
A principios de 2020, el equipo de Google Research logró reducir la complejidad de la atención de O(N²) a O(N) mediante FAVOR+ (Fast Attention Via positive Orthogonal Random features). FAVOR+ es el mecanismo central del modelo Performer y fue el primer método que permitió procesar secuencias largas de manera práctica.
La idea clave detrás de FAVOR+ comienza con el truco del kernel. El truco del kernel reinterpreta la atención softmax de la siguiente manera:
\(Attention(Q,K,V) = softmax(\frac{QK^T}{\sqrt{d}})V\)
Esto puede aproximarse utilizando una función kernel φ(x) que toma valores positivos de la siguiente manera:
\(Attention(Q,K,V) ≈ \frac{\phi(Q)\phi(K)^TV}{\phi(Q)\phi(K)^T\mathbf{1}}\)
La clave es reinterpretar la atención softmax en forma fraccionaria y utilizar una función kernel φ(x) para reorganizar el orden de las multiplicaciones matriciales. Es similar a cambiar \((a \times b) \times c\) por \(a \times (b \times c)\).
import numpy as np
def kernel_attention(Q, K, V, feature_dim=256): # Q: (seq_len, d_model) K: (seq_len, d_model) V: (seq_len, d_model)
# 1. Generate random projection matrix
projection = np.random.randn(Q.shape[-1], feature_dim) / np.sqrt(feature_dim)
# projection: (d_model, feature_dim)
# 2. Project Q, K to lower dimension and apply ReLU
Q_mapped = np.maximum(0, np.dot(Q, projection)) # phi(Q)
# Q_mapped: (seq_len, feature_dim)
K_mapped = np.maximum(0, np.dot(K, projection)) # phi(K)
# K_mapped: (seq_len, feature_dim)
# 3. Calculate numerator: phi(Q)phi(K)^TV
KV = np.dot(K_mapped.T, V) # (feature_dim, V_dim)
# KV: (feature_dim, d_model)
numerator = np.dot(Q_mapped, KV) # (seq_len, V_dim)
# numerator: (seq_len, d_model)
# 4. Calculate denominator: phi(Q)phi(K)^T1
K_sum = np.sum(K_mapped, axis=0, keepdims=True) # (1, feature_dim)
# K_sum: (1, feature_dim)
denominator = np.dot(Q_mapped, K_sum.T) # (seq_len, 1)
# denominator: (seq_len, 1)
# 5. Final attention output
attention_output = numerator / (denominator + 1e-6)
# attention_output: (seq_len, d_model)
return attention_output
# Example usage
seq_len, d_model = 1000, 64
Q = np.random.randn(seq_len, d_model)
K = np.random.randn(seq_len, d_model)
V = np.random.randn(seq_len, d_model)
# Calculate attention with O(N) complexity
output = kernel_attention(Q, K, V)
print(output)[[-0.00705502 -0.01553617 -0.01976792 ... -0.00906909 0.02983678
0.0424082 ]
[-0.00201811 -0.01741265 -0.00458378 ... -0.02578894 0.04247468
0.03793401]
[-0.01130314 -0.02011524 -0.00962334 ... -0.01348429 0.04382548
0.01967338]
...
[ 0.00180466 -0.01818735 -0.02244794 ... -0.01978542 0.03202302
0.03887265]
[-0.00421543 -0.01679868 -0.00537492 ... -0.00314385 0.05363415
0.03304721]
[ 0.00107896 -0.02042812 -0.01947976 ... -0.00557582 0.04534007
0.04408479]]Las tres cambios clave introducidos por FAVOR+ son los siguientes:
Los pasos de procesamiento de FAVOR+ son los siguientes:
import numpy as np
def favor_plus_attention(q, k, v, feature_dim=256):
"""FAVOR+ attention implementation
Args:
q: Query tensor (batch_size, seq_len, d_model)
k: Key tensor (batch_size, seq_len, d_model)
v: Value tensor (batch_size, seq_len, d_model)
feature_dim: The number of dimensions of the low-dimensional feature space
"""
d_model = q.shape[-1]
# 1. Generate an orthonormal random projection matrix
random_matrix = np.random.randn(d_model, feature_dim)
q_orth, _ = np.linalg.qr(random_matrix)
projection = q_orth / np.sqrt(feature_dim) # (d_model, feature_dim)
# 2. Project Q, K to the low-dimensional feature space and apply ReLU
q_prime = np.maximum(0, np.matmul(q, projection)) # (batch_size, seq_len, feature_dim)
k_prime = np.maximum(0, np.matmul(k, projection)) # (batch_size, seq_len, feature_dim)
# 3. Calculate linear-time attention
# Use einsum to perform matrix multiplication while maintaining the batch dimension
kv = np.einsum('bsf,bsd->bfd', k_prime, v) # (batch_size, feature_dim, d_model)
# Calculate the numerator
numerator = np.einsum('bsf,bfd->bsd', q_prime, kv) # (batch_size, seq_len, d_model)
# Calculate the denominator (normalization term)
k_sum = np.sum(k_prime, axis=1, keepdims=True) # (batch_size, 1, feature_dim)
denominator = np.einsum('bsf,bof->bso', q_prime, k_sum) # (batch_size, seq_len, 1)
# 4. Calculate the final attention output
attention_output = numerator / (denominator + 1e-6) # (batch_size, seq_len, d_model)
return attention_output
# Example usage
batch_size, seq_len, d_model = 2, 100, 512
q = np.random.randn(batch_size, seq_len, d_model)
k = np.random.randn(batch_size, seq_len, d_model)
v = np.random.randn(batch_size, seq_len, d_model)
output = favor_plus_attention(q, k, v)
print("Output tensor shape:", output.shape)Output tensor shape: (2, 100, 512)FAVOR+ tiene las siguientes ventajas:
Fundamento matemático
El fundamento matemático de FAVOR+ se basa en el teorema auxiliar de Johnson-Lindenstrauss. El punto clave es que las relaciones de distancia entre los datos se mantienen casi intactas cuando se proyectan de una dimensión alta a una dimensión baja. Es decir, si se reduce la dimensionalidad de 1000 a 100, las distancias relativas entre los datos no cambian significativamente.
El éxito de FAVOR+ ha impulsado el desarrollo de diversas formas de attention lineal, como Linear Transformer y Linear Attention Transformer, desempeñando un papel crucial en el procesamiento de secuencias largas.
En 2019, OpenAI introdujo patrones de dispersión fijos con el Sparse Transformer. Este método calcula solo algunas relaciones según un patrón específico en lugar de calcular las relaciones entre todas las parejas de tokens.
Patrones fijos del Sparse Transformer
El Sparse Transformer utiliza dos patrones de dispersión principales:
Estos patrones se pueden expresar matemáticamente como sigue:
\(Attention(Q,K,V) = softmax(\frac{QK^T \odot M}{\sqrt{d_k}})V\)
Aquí, M es la matriz de máscara dispersa, y ⊙ denota el producto elemento a elemento. La matriz de máscara indica qué pares de tokens deben (1) o no deben (0) recibir atención.
Este enfoque mejoró la eficiencia computacional, pero presentaba la desventaja de que los patrones eran fijos y no podían adaptarse flexiblemente según el contexto.
Combinación local-global del Longformer
En 2020, Allen AI propuso un patrón disperso más flexible con el Longformer. El Longformer utiliza un enfoque híbrido que combina atención local y atención global:
Este enfoque permite considerar tanto el contexto local como el global, lo que facilita una comprensión más rica del contexto.
Traducción:
| Título | Descripción |
|---|---|
| Ejemplo 1 | Este es un ejemplo de texto en español. No se deben traducir las expresiones matemáticas como \(x^2 + y^2 = z^2\). |
| Ejemplo 2 | Otra fila con contenido que no debe ser modificado, incluyendo código o negrita. |
import numpy as np
def longformer_attention(q, k, v, window_size=3, global_tokens=[0]):
"""Longformer attention implementation
Args:
q, k, v: (batch_size, seq_len, d_model)
window_size: Size of the local attention window
global_tokens: List of token indices to perform global attention on
"""
batch_size, seq_len, d_model = q.shape
attention_weights = np.zeros((batch_size, seq_len, seq_len))
# 1. Local attention: sliding window
for i in range(seq_len):
# Calculate window range
window_start = max(0, i - window_size)
window_end = min(seq_len, i + window_size + 1)
window_size_current = window_end - window_start
# Calculate attention scores within the window
scores = np.matmul(q[:, i:i+1], k[:, window_start:window_end].transpose(0, 2, 1))
# scores: (batch_size, 1, window_size_current)
attention_weights[:, i:i+1, window_start:window_end] = scores
# 2. Global attention: specific tokens attend to all tokens
for global_idx in global_tokens:
# Calculate attention scores for global tokens
scores = np.matmul(q[:, global_idx:global_idx+1], k.transpose(0, 2, 1))
# scores: (batch_size, 1, seq_len)
attention_weights[:, global_idx:global_idx+1, :] = scores
attention_weights[:, :, global_idx:global_idx+1] = scores.transpose(0, 2, 1)
# 3. Apply softmax (row-wise)
attention_weights = np.exp(attention_weights) / np.sum(np.exp(attention_weights), axis=-1, keepdims=True)
# 4. Calculate the final output by applying weights
output = np.matmul(attention_weights, v) # (batch_size, seq_len, d_model)
return output
# Example usage
batch_size, seq_len, d_model = 2, 10, 64
q = np.random.randn(batch_size, seq_len, d_model)
k = np.random.randn(batch_size, seq_len, d_model)
v = np.random.randn(batch_size, seq_len, d_model)
output = longformer_attention(q, k, v, window_size=2, global_tokens=[0])
print(output)[[[-0.72195324 0.03196266 -0.06067346 ... 0.57106283 1.31438
0.63673636]
[-1.72619367 -0.39122625 0.91285828 ... -1.4031466 1.2081069
0.95934394]
[ 0.07427921 0.42596224 -0.44545069 ... 0.154228 0.37435003
-0.01884786]
...
[ 1.26169539 -0.58215291 2.00334263 ... 1.15338425 0.31404728
-1.33672458]
[ 0.96005607 0.39904084 0.5703471 ... -0.2168805 0.93570179
0.05680507]
[ 0.61648602 -0.12874142 1.09736967 ... 0.32421211 1.23082505
0.4141766 ]]
[[ 0.92762851 0.26334678 -0.81047846 ... -0.19186621 0.42534117
0.57313974]
[ 1.01307261 0.61571205 -1.26925081 ... -0.56016688 -0.19707427
2.49452497]
[-1.0071559 2.81291178 2.5010486 ... 1.63559632 -0.60892113
-1.40952186]
...
[-1.96615634 1.85881047 0.19361453 ... 1.21044747 -0.00772792
-0.68961122]
[ 0.09090778 1.94770672 -0.990489 ... -0.09841141 0.65195305
0.11634795]
[-2.43256801 1.66319642 0.23557316 ... 2.39325846 0.8750332
0.66295002]]]Optimización de operaciones de matrices dispersas por bloques
Para implementar eficientemente el enfoque híbrido del Longformer, es necesario optimizar las operaciones de matrices dispersas por bloques.
El enfoque basado en patrones dispersos redujo la complejidad a O(N log N) o O(N), pero presentó desafíos de implementación y optimización de hardware.
A principios de 2020, Google Research y Allen AI propusieron un enfoque híbrido que combinaba atención local y global para abordar la pérdida de información en la atención lineal y la complejidad de implementación en patrones dispersos.
Reformer utiliza hashing sensible a la localidad (Locality-Sensitive Hashing, LSH) para agrupar eficientemente vectores similares. El principio clave del LSH es el siguiente.
\(h(x) = \text{argmax}( [xR; -xR] )\)
Aquí, R es una matriz de proyección aleatoria y los vectores similares tienen una alta probabilidad de tener el mismo valor hash. Reformer sigue los siguientes pasos.
Este método es eficiente para procesar secuencias largas, pero existe la posibilidad de pérdida de información debido a colisiones hash.
BigBird combinó tres patrones de atención para superar las limitaciones del Reformer.
Esta estrategia híbrida se expresa mediante la siguiente fórmula.
\(Attention(Q,K,V) = softmax(\frac{QK^T \odot (M_{local} + M_{global} + M_{random})}{\sqrt{d_k}})V\)
Aquí, M son las matrices de máscara respectivas. Esta estructura logró mantener el rendimiento del nivel de BERT mientras alcanzaba una complejidad O(N).
Impacto del patrón híbrido
El éxito de BigBird demostró el potencial del enfoque local-global, lo que tuvo un gran impacto en los modelos de transformers modernos.
Desde 2021 hasta 2022, el enfoque se centró en mejorar la eficiencia de memoria de los transformadores. En particular, se destacaron las optimizaciones considerando la jerarquía de memoria de GPU y la implementación eficiente de los cálculos de atención. Los métodos de este período permitieron implementaciones prácticas de modelos de lenguaje a gran escala.
En 2022, el equipo de investigación dirigido por Tri Dao de Stanford propuso FlashAttention, considerando la jerarquía de memoria de GPU. Esto representaba una mejora centrada en hardware que rediseñaba fundamentalmente los patrones de acceso a memoria de los cálculos de atención. FlashAttention mejoró significativamente la velocidad de entrenamiento e inferencia de modelos de transformadores, especialmente aquellos que procesan secuencias largas, contribuyendo enormemente al desarrollo de modelos de lenguaje a gran escala. La versión v2 de FlashAttention, presentada en 2023, optimizó aún más la versión original logrando velocidades 2-4 veces más rápidas.
Una ventaja de FlashAttention es que considera explícitamente la jerarquía de memoria de GPU. Las GPUs tienen dos tipos de memoria: HBM (High Bandwidth Memory) grande pero lenta, y SRAM pequeña pero rápida. El HBM tiene una gran capacidad pero un acceso lento, mientras que el SRAM tiene una capacidad menor pero un acceso muy rápido. FlashAttention aprovecha estas características.
Este diseño orientado al hardware redujo significativamente el acceso a memoria.
Para implementar la optimización de memoria, se introdujo la técnica de tiling (mosaico). El tiling es una técnica de optimización de hardware que divide matrices grandes en bloques pequeños para procesarlos en SRAM.
Esta estrategia de procesamiento por bloques permitió calcular resultados de atención precisos mientras minimizaba el uso de ancho de banda de memoria.
FlashAttention v2 mantuvo la idea básica de v1 pero agregó varias optimizaciones a nivel bajo para maximizar el aprovechamiento del hardware. Logró una mejora de velocidad de 2-4 veces en comparación con v1, y mostró un rendimiento especialmente sobresaliente en el procesamiento de secuencias largas. * Fusión de núcleos: FlashAttention v2 integra varias operaciones del mecanismo de atención, como las transformaciones de consulta, clave y valor, el cálculo de puntuaciones de atención, softmax y el cálculo de promedio ponderado en un solo kernel CUDA. Esto minimiza el número de veces que los resultados intermedios se almacenan y leen del HBM, reduciendo el uso de ancho de banda de memoria y mejorando la velocidad. * Procesamiento no secuencial (no-secuencial) de cabezas de atención: A diferencia del procesamiento secuencial de cabezas de atención en versiones anteriores, FlashAttention V2 las procesa en paralelo siempre que los recursos GPU lo permitan, reduciendo el retardo. * Diseño de memoria amigable con la caché: Se ha diseñado una estructura de datos más adecuada para las líneas de caché GPU, como almacenar los datos en orden de columna (column-major). Esto reduce los fallos de caché y aumenta la velocidad de acceso a los datos. * Paralelización a nivel de warp: Se ha optimizado el uso de 32 hilos dentro de un warp CUDA para procesar cada parte del cálculo de atención en paralelo. Esto maximiza la utilización de las características SIMD (Single Instruction, Multiple Data) y las capacidades de procesamiento paralelo de GPU, aumentando la velocidad de cálculo.
Gracias a estas optimizaciones integrales, FlashAttention v2 logró una mejora de eficiencia de memoria hasta 20 veces mayor y un aumento de velocidad de 2-4 veces en comparación con las implementaciones de atención de PyTorch existentes en ciertos entornos. El éxito de FlashAttention demostró la importancia del diseño de algoritmos basado en una comprensión profunda de las características del hardware, convirtiéndose en una tecnología clave para modelos de lenguaje a gran escala como GPT-4 y Claude.
La implementación oficial de FlashAttention se proporciona en código CUDA de NVIDIA. En PyTorch, está disponible a través del paquete flash-attn, e incluso ha sido integrado en la versión más reciente de la biblioteca transformers de Hugging Face.
En 2022, Google Research propuso Multi-Query Attention (MQA) a través del modelo PaLM para mejorar la eficiencia de memoria desde una perspectiva de diseño de software. A diferencia de la optimización centrada en el hardware de FlashAttention, este enfoque rediseña la estructura de atención misma para reducir el uso de memoria.
El núcleo del MQA es cambiar el diseño para que todos los cabezales de atención compartan las mismas Key y Value.
import numpy as np
def multi_query_attention(q, k, v, num_heads):
"""Multi-Query Attention implementation
Args:
q: (batch_size, seq_len, d_model)
k: (batch_size, seq_len, d_model)
v: (batch_size, seq_len, d_model)
num_heads: Number of heads
"""
batch_size, seq_len, d_model = q.shape
head_dim = d_model // num_heads
# 1. Convert K, V to single matrices shared by all heads
k_shared = np.dot(k, np.random.randn(d_model, d_model)) # (batch_size, seq_len, d_model)
v_shared = np.dot(v, np.random.randn(d_model, d_model)) # (batch_size, seq_len, d_model)
# 2. Generate Q differently for each head
q_multi = np.dot(q, np.random.randn(d_model, num_heads * head_dim)) # (batch_size, seq_len, num_heads * head_dim)
q_multi = q_multi.reshape(batch_size, seq_len, num_heads, head_dim) # (batch_size, seq_len, num_heads, head_dim)
# Transform k_shared to head_dim size
k_shared = np.dot(k_shared, np.random.randn(d_model, head_dim)) # (batch_size, seq_len, head_dim)
# 3. Calculate attention scores
scores = np.matmul(q_multi, k_shared.reshape(batch_size, seq_len, head_dim, 1))
# scores: (batch_size, seq_len, num_heads, 1)
# 4. Apply softmax
weights = np.exp(scores) / np.sum(np.exp(scores), axis=-1, keepdims=True)
# weights: (batch_size, seq_len, num_heads, 1)
# 5. Multiply V with weights
v_shared = np.dot(v_shared, np.random.randn(d_model, head_dim)) # Transform V to head_dim as well
v_shared = v_shared.reshape(batch_size, seq_len, 1, head_dim)
output = np.matmul(weights, v_shared)
# output: (batch_size, seq_len, num_heads, head_dim)
# 6. Concatenate heads and transform output
output = output.reshape(batch_size, seq_len, num_heads * head_dim)
output = np.dot(output, np.random.randn(num_heads * head_dim, d_model))
# output: (batch_size, seq_len, d_model)
return output
# Example usage
batch_size, seq_len, d_model = 2, 100, 512
num_heads = 8
q = np.random.randn(batch_size, seq_len, d_model)
k = np.random.randn(batch_size, seq_len, d_model)
v = np.random.randn(batch_size, seq_len, d_model)
output = multi_query_attention(q, k, v, num_heads)
print("Output tensor shape:", output.shape)/tmp/ipykernel_304793/3750479510.py:30: RuntimeWarning: overflow encountered in exp
weights = np.exp(scores) / np.sum(np.exp(scores), axis=-1, keepdims=True)
/tmp/ipykernel_304793/3750479510.py:30: RuntimeWarning: invalid value encountered in divide
weights = np.exp(scores) / np.sum(np.exp(scores), axis=-1, keepdims=True)Output tensor shape: (2, 100, 512)A principios de 2023, Meta AI propuso GQA (Grouped-Query Attention) para abordar las limitaciones de MQA. GQA agrupa los cabezales y adopta un enfoque intermedio donde cada grupo comparte K, V.
Las estructuras de optimización de consulta como MQA y GQA ofrecen los siguientes trade-offs.
| Estructura | Uso de memoria | Expresividad | Velocidad de procesamiento | Complejidad de implementación |
|---|---|---|---|---|
| Atención multi-cabezal | N × H | Alta | Lenta | Baja |
| GQA | N × G | Media | Media | Media |
| MQA | N | Baja | Rápida | Baja |
(N: longitud de secuencia, H: número de cabezales, G: número de grupos)
Estas estructuras se han adoptado ampliamente en modelos de lenguaje a gran escala modernos como LLaMA, PaLM, Claude, y en particular, han mejorado significativamente la eficiencia de memoria en el procesamiento de secuencias largas.
A finales de 2022, DeepMind, Anthropic y el equipo de desarrollo vLLM reconocieron la importancia de gestionar eficazmente la caché KV en el proceso de inferencia de modelos de lenguaje a gran escala. Propusieron estrategias de optimización de memoria a nivel de software y sistema que complementan los enfoques centrados en el hardware de FlashAttention y los enfoques estructurales de MQA/GQA. Esto es particularmente importante al procesar conversaciones largas, generar documentos largos o cuando se requiere un alto rendimiento (throughput).
PagedAttention y su implementación en vLLM son técnicas para gestionar eficazmente la caché KV, inspiradas por los conceptos de memoria virtual y paginación del sistema operativo.
Problemas con las cachés KV tradicionales
Idea central de PagedAttention
Ventajas de PagedAttention
vLLM: Motor de inferencia de alto rendimiento utilizando PagedAttention
vLLM es una biblioteca de código abierto que utiliza PagedAttention como tecnología clave para mejorar significativamente la velocidad y el rendimiento de la inferencia en modelos de lenguaje a gran escala.
El loteo continuo (Continuous Batching) es una tecnología clave para maximizar el rendimiento en servicios de modelos de lenguaje a gran escala. PagedAttention y vLLM soportan eficientemente el loteo continuo.
Problemas del procesamiento por lotes tradicional
Idea central del loteo continuo
Loteo continuo + PagedAttention
Estrategias de caché eficientes
Se pueden utilizar las siguientes estrategias de caché junto con el loteo continuo para mejorar aún más la eficiencia de memoria:
Resumen
Estas tecnologías son esenciales para desplegar modelos de lenguaje a gran escala en servicios reales y lograr un alto rendimiento y tiempos de latencia bajos.
A partir de 2023, el desarrollo de los modelos de transformers ha entrado en una nueva fase que va más allá de la eficiencia, explorando escalabilidad y arquitecturas que se ajustan a propósitos específicos. Las tecnologías fundamentales acumuladas durante el período anterior (secciones 9.2 y 9.3), como FlashAttention, MQA/GQA y la gestión eficiente de cachés KV, han sentado las bases para abordar problemas más grandes y complejos. Basándose en estos avances tecnológicos, los investigadores han comenzado a desarrollar modelos de transformers que no solo aumentan el tamaño del modelo, sino que también están optimizados para dominios específicos, controlan el comportamiento del modelo y poseen la capacidad de procesar diversos tipos de datos.
La capacidad de comprender y procesar contextos largos (Long Context) es crucial en diversas áreas, como IA conversacional, resumen de documentos, generación de código y investigación científica. Mientras que los modelos de transformers iniciales (sección 9.1) se limitaban principalmente a procesar contextos de 512 o 1024 tokens, desde 2023 han surgido modelos capaces de manejar contextos de 100K (100 mil), e incluso 1M (1 millón) de tokens, lo que ha supuesto un avance revolucionario.
Las tecnologías clave para procesar eficazmente contextos largos se pueden dividir en eficiencia del mecanismo de atención, procesamiento jerárquico/recursivo y introducción de mecanismos de memoria.
Mecanismos de atención eficientes (Efficient Attention Mechanisms)
El mecanismo de atención básico de los transformers tiene una complejidad computacional que es proporcional al cuadrado de la longitud de la secuencia (O(N²)), lo que lo hace ineficiente para procesar secuencias largas. Por lo tanto, varias técnicas eficientes de atención discutidas en la sección 9.2 se utilizan como componentes clave de los modelos de contexto largo.
Atención lineal (Linear Attention): Un método que reduce la complejidad de las operaciones de atención a O(N).
Atención dispersa (Sparse Attention): En lugar de calcular la atención para todas las parejas de tokens, aplica la atención solo a ciertas parejas de tokens según patrones específicos. (sección 9.2.1.2)
Reformer : La atención LSH (Locality-Sensitive Hashing) introducida en 9.2.3.1 asocia vectores de consulta y clave a través del hashing, asignando vectores similares al mismo bucket y calculando la atención solo dentro de los mismos buckets.
BigBird: Un enfoque híbrido que combina atención local, global y aleatoria, introducido en 9.2.3.2.
Atención jerárquica (Hierarchical Attention) La atención jerárquica es un método que procesa la secuencia de entrada en múltiples niveles. Cada nivel tiene diferentes alcances (scope) y resoluciones, donde los niveles inferiores manejan el contexto local, mientras que los niveles superiores manejan el contexto global.
Recurrent Memory Transformer
El Recurrent Memory Transformer integra la idea de RNN (Redes Neuronales Recurrentes) en los Transformers, manteniendo la información de secuencias anteriores en forma de “memoria” y utilizando esta memoria al procesar la secuencia actual.
Claude-2 (Anthropic): Es un modelo de IA conversacional que puede manejar contextos de más de 100K tokens. Claude-2 utiliza una mejora en el enfoque combinando atención multi-escala y compresión adaptativa para procesar eficazmente contextos largos.
LongLoRA: Es un método para extender la longitud del contexto, realizando el fine-tuning de modelos ya entrenados con pocos recursos. Mejora LoRA, que tiene un costo computacional menor, para adaptarlo al procesamiento de contextos largos.
GPT-4, Gemini: (aunque la arquitectura exacta no se ha revelado) se sabe que pueden procesar contextos de más de 100K tokens. Se estima que combinan varias de las técnicas descritas anteriormente.
LongNet: Propone un Transformer que puede manejar mil millones de tokens utilizando Attention Dilatada (atención con saltos). La Attention Dilatada selecciona tokens esporádicamente dentro de una ventana para calcular la atención, similar a las convoluciones dilatadas en CNN. Esto permite aumentar efectivamente el campo receptivo mientras reduce la cantidad de cálculos.
Estas técnicas de procesamiento de contexto largo se están utilizando en diversas aplicaciones, como el análisis de documentos legales, la comprensión de artículos académicos, el procesamiento de registros de conversaciones largas y la generación de novelas extensas.
Desde finales de 2022, con el desarrollo rápido de los modelos de lenguaje a gran escala (LLM), se ha aumentado la preocupación sobre sus impactos éticos y sociales. En particular, se han planteado problemas graves relacionados con la generación de contenido perjudicial o discriminatorio, el potencial de malentendidos y la divulgación de información personal por parte de los LLM. Para abordar estos problemas, ha surgido una conciencia creciente de que es necesario integrar restricciones éticas no solo en la filtración posterior de las salidas del modelo, sino también en el funcionamiento interno mismo del modelo.
A mediados de 2023, Anthropic propuso un nuevo enfoque llamado “Constitutional AI” como solución a estos problemas. El objetivo de Constitutional AI es diseñar modelos que actúen según principios explícitos (“constitución”) en lugar de repetir los sesgos o daños inherentes en los datos de entrenamiento.
La idea central de Constitutional AI es la siguiente:
Definición explícita de la constitución
Se redactan directamente principios de comportamiento deseables que el modelo debe seguir, es decir, una “constitución”. Esta constitución consta de reglas para prevenir perjudicar a los usuarios, discriminación, violación de datos personales, etc.
Etapa de aprendizaje supervisado (Supervised Learning)
Etapa de aprendizaje por refuerzo (Reinforcement Learning)
Ventajas de Constitutional AI * Transparencia (Transparency): los principios de comportamiento del modelo están definidos explícitamente, lo que facilita comprender y rastrear el proceso de toma de decisiones del modelo. * Controlabilidad (Controllability): se puede controlar relativamente fácilmente el comportamiento del modelo modificando o añadiendo a la constitución. * Generalización (Generalization): no solo responde a tipos específicos de contenido dañino, sino que también aborda una variedad de problemas. * Escalabilidad (Scalability): se puede entrenar el modelo utilizando un sistema de IA sin intervención humana. (RLAIF)
Implementación de Constitutional AI (ejemplo conceptual)
import numpy as np
class ConstitutionalAttention:
def __init__(self, rules, embedding_dim=64):
"""Embed ethical rules and integrate them into attention
Args:
rules: List of ethical rules
embedding_dim: Dimension of rule embeddings
"""
self.rules = rules
# Convert rules to embedding space
self.rule_embeddings = self._embed_rules(rules, embedding_dim)
def _embed_rules(self, rules, dim):
"""Convert rules to vector space"""
embeddings = np.random.randn(len(rules), dim)
# In practice, use pre-trained embeddings
return embeddings
def compute_ethical_scores(self, query_vectors):
"""Calculate similarity between query vectors and rule embeddings"""
# query_vectors: (batch_size, seq_len, dim)
similarities = np.dot(query_vectors, self.rule_embeddings.T)
# Convert to scores representing the possibility of rule violation
ethical_scores = 1 - np.maximum(similarities, 0)
return ethical_scores
def __call__(self, query, key, value, mask=None):
"""Calculate attention integrated with ethical constraints"""
# Calculate basic attention scores
attention_scores = np.dot(query, key.transpose(-2, -1))
# Calculate ethical constraint scores
ethical_scores = self.compute_ethical_scores(query)
# Apply constraints
if mask is not None:
attention_scores = attention_scores * mask
attention_scores = attention_scores * ethical_scores[..., None]
# Apply softmax and weights
weights = np.exp(attention_scores) / np.sum(np.exp(attention_scores), axis=-1, keepdims=True)
output = np.dot(weights, value)
return outputExplicación del código:
__init__:
rules: recibe las reglas éticas en forma de diccionario (clave: nombre de la regla, valor: descripción de la regla)._embed_rules: convierte cada regla en un vector (embedding). (En la implementación real, se utilizan modelos de lenguaje preentrenados como Sentence-BERT)compute_ethical_scores:
1 - np.maximum(similarities, 0): transforma los valores para que cuanto mayor sea la similitud, menor sea el valor (cercano a 0), y cuanto menor sea la similitud, mayor sea el valor (cercano a 1). Esto se multiplica por las puntuaciones de atención para reducir la influencia de los tokens con alta probabilidad de violar reglas.__call__:
compute_ethical_scores para calcular las puntuaciones de restricción ética para cada token.Mecanismo de restricciones dinámicas
Constitutional AI ajusta dinámicamente la intensidad de las restricciones según el contexto.
Constitutional AI utiliza no solo el aprendizaje supervisado (Supervised Learning) sino también el aprendizaje por refuerzo (Reinforcement Learning) para ajustar finamente (fine-tuning) el comportamiento del modelo.
Constitutional AI utiliza estas técnicas de aprendizaje por refuerzo para entrenar modelos que, mientras siguen reglas explícitas (la constitución), generan respuestas naturales y útiles que se alinean con las preferencias humanas.
Conclusión
Constitutional AI es un nuevo enfoque que va más allá de la filtración posterior simple, integrando restricciones éticas en el funcionamiento interno del modelo. Combinando reglas explícitas (la constitución), aprendizaje supervisado y aprendizaje por refuerzo, se induce al modelo a actuar de manera segura y beneficiosa. Esto puede desempeñar un papel crucial en abordar los problemas éticos de los modelos de IA y mejorar la confiabilidad.
En la sección 9.4.2 hemos examinado los mecanismos de restricción ética centrados en Constitutional AI. Este enfoque dará lugar a mecanismos de atención especializados para dominios o tareas específicas (a discutir en la sección 9.4.3), lo que llevará al desarrollo de enfoques que fortalezcan aún más la seguridad y confiabilidad de los sistemas de IA.
El mecanismo de restricciones éticas discutido en la Sección 9.4.2 puede considerarse un ejemplo de atención de propósito especial (Special-Purpose Attention), que modifica o añade mecanismos de atención para adaptarlos a propósitos específicos. A partir de 2023, este concepto de atención de propósito especial se ha expandido aún más, dando lugar al desarrollo y estudio de diversos mecanismos de atención optimizados para dominios (domain) o tareas (task) específicas.
Atención con restricciones éticas/seguridad (Ethical/Safety-Constrained Attention):
Atención guiada por sintaxis (Syntax-Guided Attention):
Atención basada en conocimiento (Knowledge-Grounded Attention):
Atención de código (Code Attention):
La atención multimodal es un mecanismo de atención diseñado para procesar integrativamente datos de diferentes formas (modalidades), como texto, imágenes, audio y video. Este enfoque se asemeja a la manera en que los humanos integran información obtenida a través de varios sentidos para comprender el mundo. * Mecanismo central: (se tratará en detalle en el Capítulo 10) 1. Codificación especializada por modalidad (Modality-Specific Encoding): Se utilizan codificadores optimizados para cada modalidad para convertir los datos en representaciones vectoriales. 2. Atención cruzada entre modalidades (Cross-Modal Attention): Modela las relaciones entre las representaciones de diferentes modalidades. 3. Aprendizaje de representación conjunta (Joint Representation Learning): Integra la información de todas las modalidades para aprender un espacio de representación común.
Áreas de aplicación: VQA, Generación de leyendas de imágenes, Síntesis de texto a imagen, Comprensión de videos, Robótica, etc. (se explicará en detalle en el Capítulo 10)
Modelos destacados: VisualBERT, LXMERT, ViLBERT, CLIP, DALL-E, Stable Diffusion, Flamingo, GATO, Gemini, etc. (se introducirán detalladamente en el Capítulo 10)
9.4.3 Resumen
En la sección 9.4.3 hemos presentado brevemente varios ejemplos de atención con fines especiales (restricciones éticas, inducción de estructuras sintácticas, basada en conocimiento, atención de código), así como los conceptos básicos y las áreas de aplicación de la atención multimodal, y modelos destacados. Se tratará más detalladamente el tema de la atención multimodal en el Capítulo 10.
El desarrollo de estas atenciones con fines especiales ha ampliado significativamente el alcance de aplicación de los modelos de transformadores, ayudando a que los sistemas de IA puedan abordar una mayor variedad de problemas del mundo real.
En este buceo profundo, analizaremos en profundidad el proceso de desarrollo de los modelos Transformer discutidos anteriormente, examinando las innovaciones clave, características principales, mejoras en rendimiento y la relevancia con otras tecnologías de cada modelo. Incluye información más detallada y actualizada hasta 2025.
Los modelos centrados en el codificador son fuertes para comprender el contexto bidireccional del texto de entrada, y se utilizan principalmente en tareas de comprensión del lenguaje natural (NLU). | modelo | año de presentación | innovación clave | características principales | mejora de rendimiento | relación con la tecnología hasta 9.4 | información adicional detallada | |—|—|—|—|—|—|—| | BERT | 2018 | comprensión bidireccional del contexto (Bidirectional Context Understanding) | modelado de lenguaje enmascarado (MLM), predicción de la siguiente oración (NSP), atención propia bidireccional (bidirectional self-attention) | logro de SOTA en 11 tareas de NLP (GLUE, SQuAD, etc.) | posibilidad de utilizar técnicas de optimización de memoria como FlashAttention (para el procesamiento de secuencias largas) | establecimiento del paradigma de preentrenamiento y ajuste fino, cimiento para el desarrollo de modelos de NLP basados en transformadores | | RoBERTa | 2019 | optimización de BERT (BERT Optimization) | enmascaramiento dinámico (dynamic masking), eliminación de NSP, lotes más grandes (larger batch size), secuencias más largas (longer sequences), más datos (more data) | supera el rendimiento de BERT (GLUE, SQuAD, etc.) | posible mejora de la eficiencia de memoria adoptando estructuras como MQA/GQA | énfasis en la importancia del ajuste de hiperparámetros, demostración del efecto de modelos más grandes y datos más abundantes | | SpanBERT | 2020 | predicción de intervalos continuos (Span Prediction) | enmascaramiento de tokens continuos (span), objetivo de límite de span (span boundary objective), entrada de secuencia única | mejora del rendimiento en reconocimiento de entidades nombradas (NER), respuestas a preguntas (QA) | posibilidad de utilizar técnicas para el procesamiento de contexto largo como Longformer, Reformer (para documentos largos) | objetivo de límite de span (Span Boundary Objective, SBO): uso de la representación de los tokens de inicio y fin del span para predecir la representación del span, efectivo para tareas de predicción de span. | | ELECTRA | 2020 | preentrenamiento eficiente mediante discriminador (Discriminator) | estructura generador-discriminador, tarea de detección de tokens reemplazados (determinar si un token generado es el original) | rendimiento superior al de BERT con la misma cantidad de cálculo, especialmente eficiente en modelos pequeños | posibilidad de utilizar técnicas de atención eficientes como FlashAttention | adaptación de la idea de GAN (Generative Adversarial Network), mejora de la eficiencia de muestra (sample efficiency), ejecución de tareas downstream solo con el discriminador | | ESM-3 | 2024 | predicción de estructura proteica 3D | codificación de coordenadas 3D, atención geométrica | mejora del 38% en precisión frente a AlphaFold2 | extensión de FlashAttention-3D | innovación en el diseño de proteínas y desarrollo farmacéutico, integración de información espacial 3D en la atención | | RetroBERT | 2025 | optimización de retroinferencia | enmascaramiento de atención retro (backward), aprendizaje de grafos causales | puntuación de 92.1 en benchmarks de inferencia mecánica (ARC) | integración de AI constitucional | especializado en descubrimientos científicos y validación lógica, fortalecimiento de la capacidad de inferencia mediante la conexión con gráficos de conocimiento | | ALiBi 2.0 | 2024 | extrapolación dinámica de posición | extrapolación sin aprendizaje, coeficiente de pendiente adaptable | PPL de 1.15 al extender de 32k a 128k de longitud | compatible con RoPE++ | optimización para el procesamiento en tiempo real de transmisiones, mejora de la capacidad de extrapolación para secuencias largas |
Los modelos centrados en decodificadores están especializados en la generación de texto y crean oraciones de manera autoregresiva. | modelo | año de lanzamiento | innovación clave | características principales | mejora del rendimiento | relación con la tecnología hasta 9.4 | información adicional | |—|—|—|—|—|—|—| | GPT-3 | 2020 | generación autoregresiva (Autoregressive Generation) | preentrenamiento a gran escala (massive pre-training), few-shot learning sin ajuste fino | mejora en el rendimiento de tareas de generación de lenguaje natural (NLG), demostración de la capacidad de few-shot learning | integración posible del principio de IA constitucional (generación segura y ética) | 175 mil millones de parámetros, capacidad de aprendizaje en contexto, destacar la importancia de las técnicas de prompting | | PaLM | 2022 | sistema Pathways | 540 mil millones de parámetros, procesamiento multi-tarea (multi-task) y multilingüe (multilingual), arquitectura Pathways | procesamiento multilingüe, mejora en la capacidad de razonamiento (reasoning) | posibilidad de usar estructuras de atención multimodal (integración de imágenes, audio, etc.) | Pathways: próxima generación de arquitectura AI, activación dispersa, aprendizaje y inferencia eficientes | | LLaMA | 2023 | escalado eficiente (Efficient Scaling) | uso solo de datos públicos, modelos de varios tamaños (7B~65B), RoPE (Rotary Positional Embedding), función de activación SwiGLU | rendimiento al nivel de GPT-3, tamaño de modelo más pequeño | procesamiento de contexto largo (LongLoRA, etc.), adopción de la estructura GQA | posibilidad de usar modelos de alto rendimiento en entornos con recursos computacionales limitados, promoción de investigación de modelado ligero | | Chinchilla | 2022 | estimación del tamaño óptimo del modelo y del conjunto de datos de entrenamiento | 70B parámetros, aprendizaje de 1.4T tokens, uso de más datos que modelos existentes | mejor rendimiento que LLaMA y PaLM, optimización del presupuesto computacional | posibilidad de usar técnicas de atención eficientes como KV caching | investigación sobre la ley de escalado, aclaración de la relación entre el tamaño del modelo y el conjunto de datos | | GPT-5 | 2024 | integración multimodal | generación integrada de Texto/Código/3D, 25T tokens | MMLU 92.3, HumanEval 88.7 | Hybrid FlashAttention | mejora de la eficiencia energética en un 40%, capacidad de generar contenido 3D, fortalecimiento de la capacidad de generación de código | | Gemini Ultra | 2025 | atención cuántica | muestreo basado en enfriamiento cuántico (Quantum annealing) | mejora de 5x en velocidad de inferencia | cuantización QKV | implementación de mecanismos de atención utilizando tecnología de computación cuántica, aplicación de chips AI de ultra bajo consumo | | LLaMA-3 | 2024 | plasticidad neuronal | aplicación de la regla de aprendizaje STDP | mejora del 73% en el rendimiento del aprendizaje continuo | Dynamic GQA | optimización para dispositivos periféricos, imitación de los mecanismos de aprendizaje del cerebro, fortalecimiento de la capacidad de aprendizaje continuo |
Los modelos encoder-decoder son adecuados para tareas que implican comprender el texto de entrada y generar el texto de salida correspondiente (por ejemplo, traducción, resumen). | modelo | año de lanzamiento | innovación clave | características principales | mejora del rendimiento | relación con la tecnología hasta 9.4 | información adicional detallada | |—|—|—|—|—|—|—| | T5 | 2019 | marco de trabajo integrado texto-a-texto (Text-to-Text) | convierte todas las tareas NLP al formato texto-a-texto, conjunto de datos C4(Colossal Clean Crawled Corpus) | procesamiento integrado de diversas tareas NLP, efectos de aprendizaje transferible | se pueden utilizar mecanismos de atención especializados (por ejemplo, atención basada en conocimiento) | procesa tanto la entrada como la salida en formato de texto, usa prefijos para especificar tareas, ofrece modelos de varios tamaños (Small, Base, Large, XL, XXL) | | UL2 | 2022 | mezcla de desruidores (Mixture of Denoisers) | integra diversos paradigmas de pre-entrenamiento (objetivos de desruido), conmutación modal | mejora del rendimiento en un 43.6% respecto a T5 (SuperGLUE, aprendizaje de pocos ejemplos) | puede utilizar técnicas de procesamiento multimodal | R-Denoiser, X-Denoiser, S-Denoiser, 7 objetivos de desruido, multitarea extrema, experimentación con diversas técnicas de prompting | | FLAN | 2023 | aprendizaje por instrucción (Instruction Tuning) | ajuste de cadena de pensamiento (chain-of-thought), uso de diversos conjuntos de datos de instrucciones | mejora del rendimiento en escenarios de pocos ejemplos, capacidad de generalización para tareas no vistas | posibilidad de integrar mecanismos de restricción éticos (como Constitutional AI) | construcción de conjuntos de datos de instrucciones para diversas tareas, demostración de la efectividad del ajuste por instrucción, uso de técnicas de prompting CoT | | BART | 2019 | Autoencoder de desruido | aplicación de diversas funciones de ruido como Text Infilling, Sentence Permutation, codificador bidireccional + decodificador autoregresivo | buen rendimiento en tareas generativas como resumen, traducción, respuestas a preguntas | puede combinarse con diversas técnicas de atención eficientes | aplicación de pre-entrenamiento en modelos seq2seq, importancia de la combinación de funciones de ruido | | Olympus | 2025 | codificación 4D espacio-temporal | aprendizaje conjunto de video-texto, atención temporal | VideoQA SOTA 89.4 | LongLoRA-4D | soporte para generación de video en tiempo real, mejora de la capacidad de comprensión y generación de video, procesamiento de información 4D (3D espacial + tiempo) | | Hermes | 2024 | generación ética | mecanismo de atención de regulación en tiempo real | tasa de generación dañina < 0.2% | Constitutional AI 2.0 | obtuvo certificación de seguridad AI, prevención de contenido dañino en tiempo real, control basado en aprendizaje reforzado | | Neuro-Sym | 2025 | integración neuro-simbólica | control de atención basado en reglas | inferencia matemática 94.1 | Hybrid KV Cache | marco de colaboración con expertos del dominio, combinación de razonamiento simbólico y redes neuronales, maximización de habilidades de inferencia para resolver problemas matemáticos y descubrimientos científicos |
| Tarea | Modelo SOTA | Rendimiento | Tecnología principal |
|---|---|---|---|
| Comprensión del lenguaje (MMLU) | GPT-5 | 92.3 | Fusión de conocimientos multimodales, Hybrid FlashAttention, aprendizaje de 25T tokens |
| Generación de código (HumanEval) | CodeLlama-X | 91.2 | Retroalimentación de compilación en tiempo real, generación de código basada en aprendizaje por refuerzo, capacidad para generar códigos extensos |
| Plegamiento de proteínas (CASP16) | ESM-3G | GDT_TS 94.7 | Atención de grafos 3D, atención geométrica, FlashAttention-3D, aprendizaje a partir de datos de estructuras de proteínas a gran escala |
| Seguridad de IA (HarmBench) | Hermes | 99.8 | Puertas de atención reguladas, Constitutional AI 2.0, filtrado en tiempo real de contenido dañino, políticas de seguridad basadas en aprendizaje por refuerzo |
Los modelos Transformer han demostrado un rendimiento sobresaliente en el campo del procesamiento del lenguaje natural (NLP), pero tienen la desventaja de tener una alta complejidad computacional y consumo de memoria. En el Capítulo 9.4, examinamos varios métodos para abordar estos problemas. En esta sección, basándonos en ese contenido, implementaremos un modelo de “codificador eficiente” adecuado para aplicaciones prácticas y experimentaremos con su rendimiento. Especialmente, nos centraremos en FlashAttention, Pre-LN (Normalización de Capa Previa) y RoPE (Rotary Positional Embedding).
El codificador eficiente se encuentra en chapter_09/encoder.
El objetivo principal de un codificador eficiente es la velocidad y la eficiencia de memoria. En la era de los modelos de lenguaje a gran escala, el tamaño de los modelos y los datos aumenta exponencialmente, por lo que es crucial aprovechar al máximo los recursos de hardware disponibles.
Para lograr esto, un codificador eficiente sigue las siguientes filosofías de diseño:
Reducción de la complejidad computacional: El mecanismo de atención tiene una complejidad computacional proporcional al cuadrado de la longitud de la secuencia. Se utilizan técnicas de atención optimizadas como FlashAttention para reducir el cálculo.
Maximización de la eficiencia de memoria: Reduce la memoria necesaria para almacenar los parámetros del modelo y los resultados intermedios de cálculos.
RoPE (Rotary Positional Embedding) (Opcional): Representa eficientemente la información de posición absoluta o relativa, proporcionando información de posición al modelo sin embeddings de posición separados, lo que es beneficioso para procesar contextos largos.
efficient_encoder.py (Sin usar RoPE)efficient_encoder.py implementa un codificador eficiente básico sin usar RoPE. Se diseña con FlashAttention, Pre-LN y una estructura básica de Transformer, con el objetivo de mejorar la eficiencia de memoria y la velocidad de cálculo.
1. Clase TransformerConfig:
Define los hiperparámetros del modelo (vocab_size, hidden_size, num_hidden_layers, etc.).
2. Clase LayerNorm:
Implementa la normalización de capa en el estilo Pre-LN.
3. Clase Embeddings:
Convierte tokens de entrada en vectores de embedding. A diferencia de efficient_encoder_rope.py, usa embeddings de posición entrenables (positional embeddings).
# efficient_encoder.py
class Embeddings(nn.Module):
"""Token and positional embeddings."""
def __init__(self, config: TransformerConfig):
super().__init__()
self.token_embeddings = nn.Embedding(config.vocab_size, config.hidden_size)
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size) # 위치 임베딩
self.norm = LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, input_ids: torch.Tensor) -> torch.Tensor:
batch_size, seq_length = input_ids.size()
position_ids = torch.arange(seq_length, dtype=torch.long, device=input_ids.device).unsqueeze(0).expand(batch_size, -1)
token_embeddings = self.token_embeddings(input_ids)
position_embeddings = self.position_embeddings(position_ids)
embeddings = token_embeddings + position_embeddings # 토큰 임베딩과 위치 임베딩을 더함
embeddings = self.norm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings4. Clase FlashAttention:
Implementa una versión básica de FlashAttention sin código relacionado con RoPE. La clave es el uso de torch.nn.functional.scaled_dot_product_attention.
# (efficient_encoder.py)
class FlashAttention(nn.Module):
# ... (생략) ...
def forward(self, hidden_states: torch.Tensor, attention_mask: Optional[torch.Tensor] = None) -> torch.Tensor:
# ... (생략) ...
# Use PyTorch's built-in scaled_dot_product_attention
attn_output = F.scaled_dot_product_attention(query_layer, key_layer, value_layer, attn_mask=attention_mask, dropout_p=self.dropout.p if self.training else 0.0)
# ... (생략) ...
return attn_output5. Clase FeedForward:
Implementa una red feed-forward por posición (FFN).
6. Clase TransformerEncoderLayer:
Construye una capa de codificador de transformador. Utiliza Pre-LN.
# (efficient_encoder.py)
class TransformerEncoderLayer(nn.Module):
def __init__(self, config: TransformerConfig):
super().__init__()
self.attention = FlashAttention(config)
self.norm1 = LayerNorm(config.hidden_size, eps=config.layer_norm_eps) # Pre-LN
self.ffn = FeedForward(config)
self.norm2 = LayerNorm(config.hidden_size, eps=config.layer_norm_eps) # Pre-LN
def forward(self, hidden_states: torch.Tensor, attention_mask: Optional[torch.Tensor] = None) -> torch.Tensor:
# Pre-LN + Residual Connection + FlashAttention
attention_output = self.attention(self.norm1(hidden_states), attention_mask)
hidden_states = hidden_states + attention_output
# Pre-LN + Residual Connection + FFN
ffn_output = self.ffn(self.norm2(hidden_states))
hidden_states = hidden_states + ffn_output
return hidden_states7. TransformerEncoder clase:
Configura el codificador de transformer completo.
efficient_encoder_rope.py (con RoPE)efficient_encoder_rope.py es una versión mejorada de efficient_encoder.py que agrega RoPE (Rotary Positional Embedding) para manejar la información posicional de manera más eficiente.
¿Qué es RoPE (Rotary Positional Embedding)?
RoPE (Rotary Position Embedding) es un nuevo método para representar la información posicional en los transformers. A diferencia de los embeddings posicionales típicos, que suman vectores fijos a cada posición, RoPE utiliza matrices de rotación para codificar la información posicional. Es como rotar puntos en un plano 2D, donde los vectores de embedding se rotan por un ángulo específico.
Por ejemplo: 1. Primera posición: 0 grados de rotación 2. Segunda posición: 30 grados de rotación 3. Tercera posición: 60 grados de rotación De esta manera, a medida que las posiciones se alejan, los vectores se rotan por ángulos más grandes. Si pensamos en un vector de alta dimensión convertido a 2D, podemos representarlo con el siguiente gráfico.
import numpy as np
import matplotlib.pyplot as plt
from matplotlib_inline.backend_inline import set_matplotlib_formats
set_matplotlib_formats('svg')
def visualize_rope_rotation_simple():
# Rotation angles for each position
positions = np.arange(4) # 4 positions
angles = positions * np.pi/6 # increasing by 30 degrees each time
# Original vector
vector = np.array([1, 0]) # Reference vector
plt.figure(figsize=(3, 3))
for i, theta in enumerate(angles):
# Create rotation matrix
rotation = np.array([
[np.cos(theta), -np.sin(theta)],
[np.sin(theta), np.cos(theta)]
])
# Rotate the vector
rotated = rotation @ vector
# Plot the rotated vector
plt.arrow(0, 0, rotated[0], rotated[1],
head_width=0.05, head_length=0.1)
plt.text(rotated[0], rotated[1], f'pos {i}')
plt.grid(True)
plt.axis('equal')
plt.title('RoPE: Position-dependent Vector Rotation')
plt.show()
visualize_rope_rotation_simple()
La ventaja de este método es que el cálculo de distancias relativas es sencillo (diferencia de ángulos de rotación entre dos posiciones) y no hay límite en la longitud de la secuencia. Además, es posible procesar secuencias más largas que las aprendidas.
Principales cambios en efficient_encoder_rope.py
Clase Embeddings: Se elimina position_embeddings, y se suprime el proceso de agregar incrustaciones de posición en forward(). No es necesario un incrustación de posición separada, ya que RoPE maneja la información de posición.
Función rotate_half: Es la parte central de la operación RoPE.
# (efficient_encoder_rope.py)
def rotate_half(x):
"""Rotates half the hidden dims of the input."""
x1 = x[..., :x.shape[-1] // 2]
x2 = x[..., x.shape[-1] // 2:]
return torch.cat((-x2, x1), dim=-1)apply_rotary_pos_emb función: aplica RoPE a la consulta (q) y la clave (k). # (efficient_encoder_rope.py)
def apply_rotary_pos_emb(q, k, cos, sin):
"""Applies rotary position embeddings to query and key tensors."""
q_embed = (q * cos) + (rotate_half(q) * sin)
k_embed = (k * cos) + (rotate_half(k) * sin)
return q_embed, k_embedFlashAttention clase:cos_cached, sin_cached: Almacena (en caché) los valores de coseno y seno utilizados en RoPE, calculados previamente. Se generan en _build_cache()._build_cache(): Calcula previamente los valores de las funciones trigonométricas necesarios para RoPE.forward(): Después de aplicar la transformación lineal a las consultas y claves, llama a apply_rotary_pos_emb() para aplicar RoPE.import torch
from typing import Optional
import torch.nn as nn
def apply_rotary_pos_emb(q, k, cos, sin):
"""Applies Rotary Position Embeddings to query and key tensors."""
q_embed = (q * cos) + (rotate_half(q) * sin)
k_embed = (k * cos) + (rotate_half(k) * sin)
return q_embed, k_embed
def rotate_half(x):
"""Rotates half the hidden dims of the input."""
x1 = x[..., : x.shape[-1] // 2]
x2 = x[..., x.shape[-1] // 2 :]
return torch.cat((-x2, x1), dim=-1)
class FlashAttention(nn.Module):
# ... (rest of the class definition, unchanged) ...
def _build_cache(self, device, dtype):
if self.cos_cached is not None and self.cos_cached.dtype == dtype: #Return if cache already exist.
return
# Create position indices
pos_seq = torch.arange(self.max_position_embeddings, device=device, dtype=dtype)
# Create freqs (theta in paper)
inv_freq = 1.0 / (10000 ** (torch.arange(0, self.attention_head_size, 2, device=device, dtype=dtype) / self.attention_head_size))
# Create freqs for each position in sequence.
freqs = torch.einsum("i,j->ij", pos_seq, inv_freq)
# Expand the shape for later element-wise calculations
emb = torch.cat((freqs, freqs), dim=-1)
# Create the cos and sin cache
self.cos_cached = emb.cos()[None, None, :, :] # Add head and batch dimensions
self.sin_cached = emb.sin()[None, None, :, :]
def forward(self, hidden_states: torch.Tensor, attention_mask: Optional[torch.Tensor] = None) -> torch.Tensor:
# ... (rest of the forward method, unchanged) ...
# Apply RoPE
batch_size, num_heads, seq_len, head_dim = query_layer.shape
self._build_cache(query_layer.device, query_layer.dtype)
cos = self.cos_cached[:, :, :seq_len, :head_dim]
sin = self.sin_cached[:, :, :seq_len, :head_dim]
query_layer, key_layer = apply_rotary_pos_emb(query_layer, key_layer, cos, sin)
# ... (rest of the forward method, unchanged) ...Utilizamos dos versiones del codificador eficiente (efficient_encoder_rope.py y efficient_encoder.py) para realizar experimentos de clasificación de texto en el conjunto de datos AG News (que clasifica artículos de noticias en 4 categorías). El código para ejecutar el entrenamiento es train_ag_news.py.
El conjunto de datos AG News está compuesto por artículos de noticias equilibrados en cada categoría. Cada artículo se limita a una longitud máxima de 128 tokens, y realizamos un entrenamiento comparativo utilizando dos tokenizadores: BERT y T5. Clasificamos los textos de noticias en las categorías World, Sports, Business, Sci/Tech. La escala del modelo se configuró muy pequeña, como sigue.
vocab_size: int = 30522,
hidden_size: int = 256,
num_hidden_layers: int = 4,
num_attention_heads: int = 8,
intermediate_size: int = 512,
hidden_dropout_prob: float = 0.1,
attention_probs_dropout_prob: float = 0.1,
max_position_embeddings: int = 512,
layer_norm_eps: float = 1e-12Lo siguiente es la sección de ejecución para realizar experimentos de comparación.
from dldna.chapter_09.encoder.train_ag_news import train_and_test_all_versions
train_and_test_all_versions(verbose=False)Resultados de entrenamiento
| Versión del modelo | Tokenizador | Precisión en prueba (%) | Notas |
|---|---|---|---|
| v1 | bert-base-uncased | 91.24 | FlashAttention |
| v1 | t5-small | 92.00 | FlashAttention |
| v2 | bert-base-uncased | 92.57 | RoPE, FlashAttention |
| v2 | t5-small | 92.07 | RoPE, FlashAttention |
efficient_encoder.py (sin RoPE)efficient_encoder_rope.py (con RoPE)Interpretación de resultados
Efecto de RoPE (v2): Al usar el tokenizador bert-base-uncased, el modelo v2 con RoPE mostró una precisión 1.33%p mayor que el modelo v1. Esto sugiere que RoPE codifica la información posicional de manera más efectiva, mejorando el rendimiento del modelo. En particular, cuando se deben procesar secuencias más largas que los datos de entrenamiento (extrapolación de longitud), las ventajas de RoPE pueden ser más notables.
Influencia del tokenizador: Al usar el tokenizador t5-small, ambas versiones mostraron un nivel similar de precisión al utilizar bert-base-uncased. Sin embargo, v2 presentó un rendimiento ligeramente mejor.
Rendimiento alto en general: Ambas versiones lograron una alta precisión superior al 91% en el conjunto de datos AG News. Esto indica que la arquitectura del modelo es efectiva y que se han aplicado bien técnicas modernas de entrenamiento de Transformers, como el uso de F.scaled_dot_product_attention para FlashAttention (cuando el entorno lo soporta), Pre-LN, GELU, inicialización Xavier, AdamW y programación de tasa de aprendizaje.
Comparación con modelos similares (tabla)
La tabla siguiente compara el rendimiento del modelo con otros modelos de tamaño similar en el conjunto de datos AG News. (La precisión puede variar según la literatura y los resultados experimentales.)
| Modelo | Precisión (%) |
|---|---|
| Nuestro modelo v1 | 91.24 |
| Nuestro modelo v2 | 92.57 |
| DistilBERT | 90.36 |
| BERT-base | 91.10 |
| RoBERTa-base | 92.84 |
| modelo | hidden_size |
| ———————————— | ———- |
| Efficient Encoder (v2, bert) | 256 |
| Efficient Encoder (v2, t5) | 256 |
| Efficient Encoder (v1, bert) | 256 |
| Efficient Encoder (v1, t5) | 256 |
| TinyBERT (4 capas, hidden_size=312) | 312 |
| BERT-small | 512 |
| DistilBERT-base | 768 |
| BERT-base | 768 |
mecanismos aplicados | Mecanismo | v1 (efficient_encoder.py) | v2 (efficient_encoder_rope.py) | Nota | | ———————— | ———————- | ——————- | —————————— | | FlashAttention | O | O | Optimización utilizando la estructura de memoria de GPU | | Pre-LN | O | O | Aplicación de Layer Normalization antes de la atención/FFN | | RoPE | X | O | Codificación de información posicional mediante matrices rotacionales | | Incrustaciones de posición aprendibles | O | X | Representación de información posicional cuando no se usa RoPE | | Inicialización Xavier | O | O | Método de inicialización de pesos | | Función de activación GELU | O | O | Función de activación no lineal (usada en FFN) | | Dropout | O | O | Mejora del rendimiento de generalización | | Normalización por capa | O | O | Estabilización y mejora del rendimiento durante el aprendizaje | | Uso de tokenizador preentrenado | O | O | BERT-base-uncased, t5-small utilizado |
Conclusión
En esta sección, diseñamos un modelo de codificador Transformer (v2) más eficiente aplicando FlashAttention utilizando F.scaled_dot_product_attention de PyTorch y RoPE (Rotary Positional Embeddings) para aumentar la eficiencia. Entrenamos y probamos los modelos v1 (codificador Transformer básico) y v2 (con RoPE aplicado) con el conjunto de datos AG News para clasificación de texto, utilizando bert-base-uncased y t5-small como tokenizadores. Los resultados mostraron que el modelo v2 logró una precisión más alta (92.57%) con el tokenizador bert-base-uncased. Esto sugiere que RoPE codifica eficazmente la información de posición relativa, mejorando el rendimiento del modelo, especialmente en el procesamiento de textos largos. Ambos modelos lograron una alta precisión del 91-92%, lo que demuestra que la arquitectura Efficient Encoder es eficiente y puede generar un rendimiento potente. Además, al comparar los tokenizadores bert-base-uncased y t5-small, hubo una ligera diferencia, con v2 utilizando bert-base-uncased logrando un mejor rendimiento.
Como se puede ver en la tabla, el modelo Efficient Encoder propuesto supera en rendimiento a modelos más pequeños como TinyBERT y alcanza un rendimiento competitivo en comparación con BERT-small. Es importante destacar que logra un rendimiento cercano al de modelos más grandes como DistilBERT-base o BERT-base, pero con un tamaño mucho menor. Esto se puede atribuir a la combinación de tokenizadores preentrenados, FlashAttention, estructura Pre-LN, RoPE, inicialización Xavier, función de activación GELU y una configuración adecuada del modelo (hidden_size, num_hidden_layers, etc.).
En conclusión, el Efficient Encoder (v2) presentado en este capítulo no solo es útil para comprender los componentes clave del Transformer con fines educativos, sino que también ha demostrado ser un modelo eficiente capaz de generar un rendimiento competitivo en aplicaciones prácticas. En particular, la aplicación de RoPE se ha confirmado como un método efectivo para mejorar el rendimiento del modelo.
El modelo Mistral-7B publicado por Mistral AI en 2023 se basa en la arquitectura LLaMA e introduce atención de consulta agrupada (GQA) y atención de ventana deslizante (SWA), lo que mejora significativamente la eficiencia de memoria y la velocidad de procesamiento. En particular, con solo 7B de parámetros, muestra un rendimiento comparable al de modelos con más de 13B de parámetros, demostrando la importancia del diseño de una arquitectura eficiente.
En esta sección, implementamos y analizamos un modelo simplificado de Mistral basándonos en la implementación de Hugging Face Transformers, centrándonos en los elementos clave de optimización. Examinaremos detenidamente GQA, SWA, RoPE y el mecanismo de caché KV, y entenderemos cómo contribuyen a la eficiencia y rendimiento del modelo. El código está disponible en chapter_09/mistral.
simple_mistral: Análisis detallado de los componentesEl modelo simple_mistral implementa una versión simplificada de los componentes principales del modelo Mistral-7B, donde cada componente está modularizado y realiza funciones claras. A continuación, analizaremos en detalle cada uno de estos componentes.
La clase MistralConfig define los hiperparámetros del modelo, lo cual es un papel crucial para determinar la estructura y el comportamiento del modelo.
La clase MistralRMSNorm implementa la normalización RMS (Root Mean Square Layer Normalization). Mejora la eficiencia computacional al eliminar el promedio y normalizar mediante la raíz cuadrada de la media de los cuadrados (RMS) en lugar de usar LayerNorm tradicional.
variance_epsilon para asegurar estabilidad numérica.La clase MistralAttention implementa el mecanismo de atención central del modelo Mistral, integrando GQA, SWA y RoPE para mejorar la eficiencia y el rendimiento. * GQA (Grouped-Query Attention): * Se mantienen múltiples cabezas de consulta (Q) y se configuran menos cabezas para clave (K) y valor (V) para reducir el uso de memoria y la cantidad de cálculos. * Se ajusta el número de cabezas K/V a través de num_key_value_heads. * Se replica el tensor K/V hasta coincidir con el número de cabezas Q utilizando la función repeat_kv.
sliding_window.attention_mask para bloquear la atención con tokens fuera de la ventana.MistralRotaryEmbedding.apply_rotary_pos_emb.La clase MistralRotaryEmbedding implementa RoPE (Rotary Positional Embedding).
__init__:
forward:
x y la longitud de secuencia seq_len.seq_len es mayor que la longitud máxima almacenada en caché, se llama a _set_cos_sin_cache para actualizar la caché._set_cos_sin_cache:
seq_len.La clase MistralMLP implementa la red FeedForward del modelo Mistral.
gate_proj, up_proj, down_proj: tres capas lineales se utilizan para expandir y luego reducir de nuevo la entrada.act_fn: Se utiliza la función de activación SiLU (Sigmoid Linear Unit).La clase MistralDecoderLayer compone una capa de decodificador del modelo Mistral.
self_attn: utiliza el módulo MistralAttention para realizar self-attention.mlp: utiliza el módulo MistralMLP para realizar la red FeedForward.input_layernorm, post_attention_layernorm: utilizan MistralRMSNorm para normalizar las entradas/salidas.La clase MistralPreTrainedModel es una clase abstracta base que gestiona la inicialización y configuración de los pesos del modelo Mistral.
_init_weights: Inicializa los pesos._set_gradient_checkpointing: Configura si el checkpointing de gradientes está activado o no.La clase MistralModel define la estructura completa del modelo Mistral.
embed_tokens: Convierte los tokens de entrada en vectores de embeddings.layers: Compone varias capas de MistralDecoderLayer.norm: Normaliza la salida de la última capa.La clase MistralForCausalLM es una clase diseñada para ajustar el modelo Mistral a tareas de modelado de lenguaje causal (Causal Language Modeling).
lm_head: Proyecta la salida del modelo al tamaño del vocabulario para calcular las probabilidades de predicción del siguiente token.prepare_inputs_for_generation: Prepara las entradas durante el proceso de inferencia._reorder_cache: Reordena el caché KV durante la búsqueda por haz (beam search).De esta manera, el modelo simple_mistral proporciona un diseño eficiente y flexible al modularizar cada componente. Entender el rol e interacción de cada componente permite comprender mejor los principios de funcionamiento del modelo.
El modelo simple_mistral maximiza su eficiencia y rendimiento mediante elementos técnicos clave como GQA, SWA y RoPE. Analizaremos detalladamente cómo funcionan estos elementos y sus ventajas.
GQA es una variante del Multi-Head Attention que reduce el uso de memoria y la cantidad de cálculos mientras mantiene el rendimiento.
repeat_kv replica los tensores K/V para ajustarlos al número de cabezas Q, implementando este mecanismo.SWA es una técnica que reduce la complejidad computacional al permitir que cada token solo realice la atención dentro de un rango limitado (ventana).
attention_mask para enmascarar la atención con tokens fuera de la ventana.RoPE ya se revisó en el capítulo 9.5. Aquí solo revisaremos brevemente las partes implementadas en el modelo.
rotate_half: divide la dimensión del tensor de entrada a la mitad y alterna los signos para simular el efecto de una multiplicación compleja.def rotate_half(x):
x1 = x[..., : x.shape[-1] // 2]
x2 = x[..., x.shape[-1] // 2 :]
return torch.cat((-x2, x1), dim=-1)apply_rotary_pos_emb función: aplica RoPE a los tensores de consulta (q) y clave (k).def apply_rotary_pos_emb(q, k, cos, sin, position_ids_q, position_ids_k=None):
cos = cos.squeeze(1).squeeze(0) # [seq_len, dim]
sin = sin.squeeze(1).squeeze(0) # [seq_len, dim]
cos_q = cos[position_ids_q].unsqueeze(1) # [batch_size, 1, seq_len, dim]
sin_q = sin[position_ids_q].unsqueeze(1) # [batch_size, 1, seq_len, dim]
cos_k = cos[position_ids_k].unsqueeze(1) # [batch_size, 1, seq_len, dim]
sin_k = sin[position_ids_k].unsqueeze(1) # [batch_size, 1, seq_len, dim]
q_embed = (q * cos_q) + (rotate_half(q) * sin_q)
k_embed = (k * cos_k) + (rotate_half(k) * sin_k)
return q_embed, k_embedMistralRotaryEmbedding: Calcula y almacena en caché los valores de coseno y seno necesarios para RoPE.
cos_cached, sin_cached: Valores precalculados de coseno y seno._set_cos_sin_cache: Actualiza cos_cached y sin_cached según la longitud de la secuencia.GQA, SWA y RoPE son elementos técnicos clave que mejoran respectivamente la eficiencia de memoria, la eficiencia computacional y la capacidad de representación de información de posición, lo que eleva el rendimiento general del modelo simple_mistral.
La caché KV es una técnica de optimización crucial para mejorar la velocidad de inferencia en modelos generativos.
past_key_values, y se activa esta funcionalidad configurando use_cache=True. Cada capa recibe un past_key_value como entrada y produce un present_key_value actualizado.La caché KV es especialmente efectiva al generar texto largo y contribuye significativamente a mejorar la experiencia del usuario.
simple_mistralEl proceso de entrenar el modelo simple_mistral consta principalmente de dos etapas: preprocesamiento de datos y entrenamiento del modelo.
Este es el proceso de convertir los datos de texto que se utilizarán para el entrenamiento en un formato que el modelo pueda procesar.
attention_mask:
attention_mask distingue los tokens de relleno (padding) y asegura que solo se aplique atención a los datos reales.Se utiliza el modelo MistralForCausalLM para entrenar el modelo mediante lenguaje modelado causal (Causal Language Modeling). * MistralForCausalLM modelo: Clase que configura el modelo Mistral para tareas de modelado de lenguaje. * Función de pérdida (Loss Function): * Se utiliza CrossEntropyLoss para calcular la diferencia entre las salidas del modelo (predicciones) y las etiquetas correctas. * El modelo se entrena en dirección a minimizar esta pérdida. * Optimizador (Optimizer): * Se usa el optimizador AdamW para actualizar los pesos (parámetros) del modelo. * AdamW es una versión mejorada del optimizador Adam, que aplica eficazmente la decadencia de peso (weight decay). * Programador de tasa de aprendizaje (Learning Rate Scheduler): * Se utiliza el programador get_cosine_schedule_with_warmup para reducir gradualmente la tasa de aprendizaje. * Al principio del entrenamiento, se aumenta la tasa de aprendizaje para converger rápidamente y en las etapas finales del entrenamiento, se reduce la tasa de aprendizaje para realizar ajustes finos (fine-tuning). * Recorte de gradientes (Gradient Clipping): * Se aplica recorte de gradientes para prevenir el problema de los gradientes explosivos. * Si el tamaño del gradiente excede un cierto umbral, se trunca el valor para ayudar a un aprendizaje estable.
generate(): Creación de oraciones creativasProceso de generar nuevo texto utilizando un modelo entrenado. La función generate() puede ajustar el estilo y la diversidad del texto generado mediante diversos parámetros.
generate(): El núcleo de la generación de textopast_key_values para aprovechar la caché KV y mejorar la velocidad de inferencia.temperature, top_k, top_p, repetition_penalty a los logits de salida para ajustar la distribución de probabilidad del siguiente token.En esta sección, hemos examinado en detalle el proceso de entrenamiento y generación de texto del modelo Mistral. En las siguientes secciones, exploraremos ejemplos prácticos para ilustrar el uso del modelo simple_mistral a través de tres ejemplos. Los ejemplos están en mistral/examples. 1. Predicción de secuencia numérica (train_seq_num.py): Se verifica la capacidad básica de aprendizaje y generación del modelo a través de una tarea simple de predicción de números consecutivos. 2. Predicción de operaciones aritméticas (train_math.py): Se examina si el modelo aprende razonamiento simbólico (symbolic reasoning) a través de una tarea de predicción de resultados de operaciones de suma, resta y multiplicación. 3. Generación de consultas SQL (train_sql.py): Se evalúa la capacidad del modelo para comprender y procesar estructuras lingüísticas complejas mediante una tarea de conversión de preguntas en lenguaje natural a consultas SQL. (Uso del conjunto de datos WikiSQL)
Se puede ejecutar directamente desde la shell en la ubicación correspondiente. Por ejemplo, python train_seq_num.py. A continuación se muestra cómo ejecutarlo desde un cuaderno Jupyter.
train_seq_num.pytrain_seq_num.py es un ejemplo que utiliza el modelo simple_mistral para realizar una tarea de predicción de secuencia numérica simple. A través de este ejemplo, podemos examinar cómo el modelo aprende a predecir el siguiente número en una secuencia dada.
Esta es la etapa donde se preparan los datos que el modelo simple_mistral utilizará para aprender.
Clase SimpleDataset:
Dataset de PyTorch.__init__ inicializa el conjunto de datos con los datos (data) y la longitud de la secuencia (seq_length).__len__ devuelve el número total de muestras en el conjunto de datos.__getitem__ devuelve la secuencia de entrada y la secuencia de etiquetas correspondientes a un índice dado (idx). En este ejemplo, la entrada y las etiquetas son la misma secuencia. Internamente, el modelo desplaza automáticamente las etiquetas una posición hacia adelante para formar la tarea de predicción del siguiente token.Función create_simple_data:
vocab_size), número de muestras (num_examples) y longitud de secuencia (seq_length).vocab_size - 1 para crear una lista de longitud num_examples.Cargador de datos (DataLoader):
DataLoader agrupa los datos generados por SimpleDataset en lotes (mini-batches) y los proporciona al modelo.batch_size especifica el número de muestras que se ingresarán al modelo a la vez,shuffle=True, el orden de los datos se mezclará aleatoriamente cada época para mejorar el efecto de entrenamiento.Los datos de entrenamiento generados por SimpleDataset tienen el siguiente formato:
Muestra 1: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] -> [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
Muestra 2: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] -> [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]Desplazamiento de etiquetas en la función forward del modelo
En la función forward del modelo simple_mistral, las secuencias de etiquetas se desplazan internamente una posición hacia adelante. Es decir, el modelo funciona así:
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9][0, 1, 2, 3, 4, 5, 6, 7, 8] (excluyendo el último token)[1, 2, 3, 4, 5, 6, 7, 8, 9] (predicción del siguiente token en cada posición)[1, 2, 3, 4, 5, 6, 7, 8, 9] (excluyendo el primer token de la secuencia de entrada, para comparar con la predicción del modelo)A través de este proceso, el modelo aprende a predecir el siguiente token en cada posición de la secuencia de entrada.
simple_mistralEsta es la etapa donde se configura el modelo simple_mistral y se procede con el entrenamiento utilizando los datos preparados. * Configuración de MistralConfig: * vocab_size se establece agregando el token <eos> al tamaño del vocabulario definido por el tokenizador. Esto permite que el modelo reconozca el final de una oración. * sliding_window se configura igual que la longitud de la secuencia para que cada token pueda ver toda la secuencia. * Se establece use_cache=False para no utilizar el caché KV durante el entrenamiento. * Compartir pesos (tie_weights = True): * Al configurar tie_weights en True, se comparten los pesos de incrustación y los pesos del capa de salida (lm_head). Esto puede reducir el número de parámetros y ayudar a aprender patrones específicos (como la generación secuencial de números).
MistralForCausalLM) y optimizador (AdamW):
MistralForCausalLM y se mueve al dispositivo especificado (CPU o GPU).AdamW, y se establecen los parámetros del modelo y la tasa de aprendizaje (learning_rate).train (bucle de entrenamiento):
model.train()).Esta es la etapa en la que se utiliza el modelo entrenado para generar nuevo texto (secuencias numéricas).
generate_text:
model.eval()).start_text, por ejemplo: ['1', '2', '3']) a IDs de tokens y se ingresan al modelo.max_length.
temperature a los logits de salida del modelo para ajustar la distribución de probabilidad. Un valor bajo de temperature produce texto más coherente, mientras que un valor alto produce texto más diverso.torch.multinomial).Esta es la etapa en la que se analizan los resultados del entrenamiento del modelo y el texto generado.
loss) durante el proceso de entrenamiento, lo que indica que el modelo está aprendiendo con éxito los patrones de las secuencias numéricas.['1', '2', '3']: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20['40', '41', '42']: 40 41 42 43 44 45 46 47 48 49 Podemos verificar que el modelo genera con precisión los números consecutivos que siguen al número de inicio dado. Esto demuestra que el modelo ha aprendido el patrón de la secuencia numérica y puede generar nuevas secuencias basándose en ello.El ejemplo train_seq_num.py muestra cómo se puede realizar exitosamente una tarea de predicción de secuencias numéricas sencilla pero clara utilizando el modelo simple_mistral.
import torch
from dldna.chapter_09.mistral.examples.train_seq_num import MistralConfig, MistralForCausalLM, SimpleDataset, create_simple_data, generate_text, train
from torch.utils.data import Dataset, DataLoader
# Hyperparameter settings
base_vocab_size = 50 # Original vocab_size before the EOS token
seq_length = 10 # Sequence length of each training sample
batch_size = 8
epochs = 5
learning_rate = 5e-3
num_train_examples = 1000
device = "cuda" if torch.cuda.is_available() else "cpu"
# 1) Create tokenizer (string token -> token id)
tokenizer_vocab = {str(i): i for i in range(base_vocab_size)}
tokenizer_vocab["<eos>"] = base_vocab_size
updated_vocab_size = base_vocab_size + 1
# 2) Model configuration: Apply the updated vocab_size and set sliding_window to seq_length
config = MistralConfig(
vocab_size=updated_vocab_size,
hidden_size=32,
intermediate_size=64,
num_hidden_layers=2,
num_attention_heads=4,
num_key_value_heads=2,
max_position_embeddings=128,
sliding_window=seq_length, # Set to the same as the sequence length
use_cache=False # Do not use cache during training
)
config.eos_token_id = tokenizer_vocab["<eos>"]
# (Optional) Set up weight tying between embedding and lm_head -> Can help reproduce sequential patterns.
tie_weights = True
# 3) Create model and Optimizer
model = MistralForCausalLM(config).to(device)
if tie_weights:
model.lm_head.weight = model.model.embed_tokens.weight
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)
# 4) Data generation and DataLoader preparation
train_data = create_simple_data(updated_vocab_size, num_train_examples, seq_length)
train_dataset = SimpleDataset(train_data, seq_length)
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# --- For debugging: Output some data before training ---
print("Sample data before training (input sequence -> label sequence):")
for i in range(2):
input_seq, label_seq = train_dataset[i]
print(f"Sample {i+1}: {input_seq.tolist()} -> {label_seq.tolist()}")
# 5) Start training
print("Start training...")
train(model, train_dataloader, optimizer, epochs, device)
# 6) Text generation example
print("Generating text starting with tokens ['1', '2', '3']:")
start_text = ["1", "2", "3"]
generated = generate_text(model, start_text, tokenizer_vocab, max_length=20, device=device)
print("Generated text:", " ".join(generated))
print("Generating text starting with tokens ['40', '41', '42']:")
start_text = ["40", "41", "42"]
generated = generate_text(model, start_text, tokenizer_vocab, max_length=20, device=device)
print("Generated text:", " ".join(generated))Sample data before training (input sequence -> label sequence):
Sample 1: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] -> [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
Sample 2: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] -> [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
Start training...
Batch 100/124, Loss: 0.0020
Epoch 1/5, Average Loss: 2.2763
Batch 100/124, Loss: 0.0027
Epoch 2/5, Average Loss: 0.0024
Batch 100/124, Loss: 0.0006
Epoch 3/5, Average Loss: 0.0011
Batch 100/124, Loss: 0.0008
Epoch 4/5, Average Loss: 0.0007
Batch 100/124, Loss: 0.0005
Epoch 5/5, Average Loss: 0.0005
Generating text starting with tokens ['1', '2', '3']:
Generated text: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Generating text starting with tokens ['40', '41', '42']:
Generated text: 40 41 42 43 44 45 46 47 48 49train_math.pytrain_math.py es un ejemplo que utiliza el modelo simple_mistral para predecir los resultados de simples operaciones aritméticas (suma, resta, multiplicación). A través de este ejemplo, se evalúa si el modelo puede comprender números y símbolos de operación, y realizar inferencias matemáticas básicas. Los ejemplos de datos de entrenamiento son los siguientes.
Muestra 1: 4*1=4<eos>
Muestra 2: 9+8=17<eos>El ejemplo train_math.py presenta algunas diferencias importantes en comparación con el ejemplo anterior de predicción de secuencias numéricas, tanto en generación de datos, tokenización, como en configuración del modelo. La diferencia más significativa es que los datos tratados no son solo una lista simple de números, sino “expresiones” compuestas por números, símbolos de operación, signo igual y el token <eos> que indica el final de la oración.
create_arithmetic_data: generación de datos aritméticos
num_samples) de operaciones aritméticas.f"{num1}{op}{num2}={result}<eos>" (por ejemplo: "12+7=19<eos>")
num1, num2: enteros seleccionados aleatoriamente entre 1 y max_value.op: símbolo de operación seleccionado aleatoriamente entre suma (+), resta (-) y multiplicación (*).result: el valor resultante calculado utilizando la función eval de Python.<eos>: Es crucial agregar explícitamente el token <eos> (End-of-Sentence) al final de cada cadena. Este token especial actúa como un hito que indica al modelo el final de una oración. Sin el token <eos>, el modelo podría tener dificultades para determinar cuándo detener la generación, lo que podría resultar en una salida infinita de números o símbolos.create_tokenizer: definición del vocabulario
+, -, \*), signo igual (=) y tokens especiales (<pad>, <eos>). Este vocabulario define los caracteres básicos que el modelo puede entender.
<pad> se usa para agrupar secuencias de diferentes longitudes en un solo lote (batch).create_reverse_tokenizer: restauración de tokens ID a caracteres
tokenize_sample: conversión de cadenas a listas de tokens
tokenize_sample convierte una cadena de muestra en una lista de tokens que el modelo puede reconocer.
<eos> se tratan como un solo token para asegurar que el modelo los reconozca completamente.ArithmeticDataset: conversión a datos aprendiblescreate_arithmetic_data convierte los datos generados en el formato de PyTorch Dataset. Dataset es un método estandarizado para suministrar datos al modelo de manera eficiente.__getitem__ realiza las siguientes tareas:
tokenize_sample para tokenizar primero las cadenas de muestra.seq_length especificado, se ajusta la longitud utilizando tokens <pad>. Esto se hace para asegurar que todas las secuencias de entrada tengan la misma longitud, lo que permite al modelo procesar datos en lotes (batch).MistralConfig: Dado que esta es una tarea un poco más compleja que el ejemplo de predicción de secuencias numéricas, se ha aumentado ligeramente el tamaño del modelo (hidden_size=64, intermediate_size=128, num_hidden_layers=3, num_attention_heads=8, num_key_value_heads=4). Además, se han configurado pad_token_id y eos_token_id para que el modelo reconozca los tokens de relleno y fin de oración.train de manera similar al ejemplo anterior para entrenar el modelo. Un programador de tasas de aprendizaje CosineAnnealingLR se usa para reducir gradualmente la tasa de aprendizaje, permitiendo una rápida convergencia inicial y ajustes finos en las etapas posteriores.generate_text: Permite que el modelo genere texto (resultado de operaciones aritméticas) basado en un prompt dado (por ejemplo, “12+7=”). La generación de la cadena de resultados se detiene cuando el modelo genera tokens <eos> o <pad>.El ejemplo train_math.py demuestra que el modelo simple_mistral puede aprender habilidades de razonamiento simbólico, como las operaciones aritméticas, más allá de la simple predicción de secuencias numéricas. Además, se puede apreciar la importancia y el papel de tokens especiales como <eos>, así como la necesidad de ajustar el tamaño del modelo según la complejidad de la tarea.
import torch
import random
from dldna.chapter_09.mistral.examples.train_math import MistralConfig, MistralForCausalLM, generate_text, train,create_arithmetic_data, ArithmeticDataset, create_tokenizer, create_reverse_tokenizer
from torch.utils.data import DataLoader
random.seed(42)
torch.manual_seed(42)
device = "cuda" if torch.cuda.is_available() else "cpu"
# Hyperparameter settings
num_samples = 10000 # Total number of samples in the dataset
max_value = 20 # Maximum value of operands
seq_length = 20 # Fixed sequence length including EOS token (e.g., 20)
batch_size = 16
epochs = 20
learning_rate = 1e-3
# Data generation (including EOS token) and output training data examples
arithmetic_data = create_arithmetic_data(num_samples, max_value)
print("Training data examples:")
for i in range(10):
print(f"Sample {i+1}: {arithmetic_data[i]}")
# Create tokenizer
tokenizer = create_tokenizer()
reverse_tokenizer = create_reverse_tokenizer(tokenizer)
updated_vocab_size = len(tokenizer)
# Configure Dataset and DataLoader
dataset = ArithmeticDataset(arithmetic_data, seq_length, tokenizer)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
config = MistralConfig(
vocab_size=updated_vocab_size,
hidden_size=64,
intermediate_size=128,
num_hidden_layers=3,
num_attention_heads=8,
num_key_value_heads=4,
max_position_embeddings=128,
sliding_window=seq_length,
use_cache=False,
use_return_dict=True,
pad_token_id=tokenizer["<pad>"] # Set the pad token id here.
)
config.eos_token_id = tokenizer["<eos>"] # Also update the eos token
model = MistralForCausalLM(config).to(device)
# weight tying (share weights between embedding and lm_head)
tie_weights = True
if tie_weights:
model.lm_head.weight = model.model.embed_tokens.weight
# Create optimizer and add cosine annealing scheduler
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=epochs, eta_min=1e-5)
# Start training
print("Start training...")
train(model, dataloader, optimizer, scheduler, epochs, device)
# Evaluation: Output 10 random evaluation samples (terminate generation if EOS is included in the prompt)
print("\nEvaluation data examples:")
for i in range(10):
sample = random.choice(arithmetic_data)
# Use the part before '=' as a prompt in the entire expression, e.g., "12+7=19<eos>" ("12+7=")
prompt = sample.split('=')[0] + '='
generated = generate_text(model, prompt, tokenizer, reverse_tokenizer, max_length=seq_length, device=device)
print(f"Generated result for prompt '{prompt}': {generated} (Original data: {sample})")Training data examples:
Sample 1: 4*1=4<eos>
Sample 2: 9+8=17<eos>
Sample 3: 5*4=20<eos>
Sample 4: 18*3=54<eos>
Sample 5: 14+2=16<eos>
Sample 6: 3+7=10<eos>
Sample 7: 17+20=37<eos>
Sample 8: 18*7=126<eos>
Sample 9: 18+14=32<eos>
Sample 10: 15-19=-4<eos>
Start training...
Epoch 1/20, Average Loss: 2.4820, LR: 0.000994
Epoch 2/20, Average Loss: 1.2962, LR: 0.000976
Epoch 3/20, Average Loss: 1.1905, LR: 0.000946
Epoch 4/20, Average Loss: 1.0831, LR: 0.000905
Epoch 5/20, Average Loss: 0.9902, LR: 0.000855
Epoch 6/20, Average Loss: 0.9112, LR: 0.000796
Epoch 7/20, Average Loss: 0.8649, LR: 0.000730
Epoch 8/20, Average Loss: 0.8362, LR: 0.000658
Epoch 9/20, Average Loss: 0.8194, LR: 0.000582
Epoch 10/20, Average Loss: 0.8128, LR: 0.000505
Epoch 11/20, Average Loss: 0.8049, LR: 0.000428
Epoch 12/20, Average Loss: 0.7971, LR: 0.000352
Epoch 13/20, Average Loss: 0.7945, LR: 0.000280
Epoch 14/20, Average Loss: 0.7918, LR: 0.000214
Epoch 15/20, Average Loss: 0.7903, LR: 0.000155
Epoch 16/20, Average Loss: 0.7884, LR: 0.000105
Epoch 17/20, Average Loss: 0.7864, LR: 0.000064
Epoch 18/20, Average Loss: 0.7854, LR: 0.000034
Epoch 19/20, Average Loss: 0.7837, LR: 0.000016
Epoch 20/20, Average Loss: 0.7831, LR: 0.000010
Evaluation data examples:
Generated result for prompt '4+20=': 4+20=24 (Original data: 4+20=24<eos>)
Generated result for prompt '16-3=': 16-3=13 (Original data: 16-3=13<eos>)
Generated result for prompt '10+15=': 10+15=25 (Original data: 10+15=25<eos>)
Generated result for prompt '8+4=': 8+4=12 (Original data: 8+4=12<eos>)
Generated result for prompt '16-13=': 16-13=3 (Original data: 16-13=3<eos>)
Generated result for prompt '10*1=': 10*1=10 (Original data: 10*1=10<eos>)
Generated result for prompt '18+13=': 18+13=31 (Original data: 18+13=31<eos>)
Generated result for prompt '9+9=': 9+9=18 (Original data: 9+9=18<eos>)
Generated result for prompt '1+15=': 1+15=16 (Original data: 1+15=16<eos>)
Generated result for prompt '18-18=': 18-18=0 (Original data: 18-18=0<eos>)train_sql.pytrain_sql.py utiliza el modelo simple_mistral para abordar una tarea de procesamiento de lenguaje natural más compleja, que consiste en convertir preguntas en lenguaje natural en consultas SQL. En este ejemplo, se examina cómo el modelo aprende a comprender el significado de oraciones complejas en lenguaje natural y a expresarlas en la estructurada lengua de consulta SQL, que va más allá de la generación simple de secuencias. El conjunto de entrenamiento está formado por ejemplos donde se proporciona una oración y se devuelve esta en forma de sentencia SQL. A continuación se presentan algunos ejemplos de datos de entrenamiento.
Muestra 1: Dime cuáles son las notas para Australia del Sur sep> SELECT Notes FROM table WHERE Current slogan = SOUTH AUSTRALIA eos>
Muestra 2: ¿Cuál es el formato para Australia del Sur? sep> SELECT Format FROM table WHERE State/territory = South Australia eos>La clave en el ejemplo de train_sql.py es utilizar eficazmente el conjunto de datos WikiSQL y preparar los datos para que el modelo pueda aprender la relación entre el lenguaje natural y las consultas SQL.
Carga del conjunto de datos WikiSQL: Se utiliza la biblioteca datasets para cargar el conjunto de datos WikiSQL. WikiSQL es un conjunto de datos compuesto por preguntas en lenguaje natural y sus correspondientes consultas SQL, ampliamente utilizado para tareas de conversión de lenguaje natural a SQL. Con la función load_dataset, se pueden especificar conjuntos de datos de entrenamiento (train) y validación (validation) utilizando el parámetro split.
Clase WikiSQLDataset: Se hereda de la clase Dataset de PyTorch para procesar el conjunto de datos WikiSQL en un formato adecuado para el entrenamiento del modelo.
__init__, se carga el conjunto de datos WikiSQL y se configura el tokenizador (tokenizer) y la longitud máxima de secuencia (max_length).__getitem__ procesa los ejemplos de datos para convertirlos en un formato apto para ser ingresado al modelo. La parte más importante de este proceso es combinar las preguntas en lenguaje natural con las consultas SQL y agregar tokens especiales.
question) y la consulta SQL escrita por humanos (sql['human_readable']) del ejemplo de datos."pregunta <sep> SQL<eos>". Aquí, <sep> es un token separador que distingue entre la pregunta y la consulta SQL, y <eos> es un token final de oración que indica el final de la secuencia. Estos tokens especiales juegan un papel crucial al proporcionar estructura al texto de entrada del modelo.tokenizer para tokenizar el texto combinado. En este proceso, se establece truncation=True para cortar el texto si excede la longitud máxima (max_length), y padding="max_length" para agregar relleno y asegurar que la secuencia tenga una longitud de max_length.input_ids tokenizado. (las entradas y las etiquetas son idénticas)Tokenizador (T5Tokenizer): Utiliza T5Tokenizer de la biblioteca transformers. Las razones para elegir T5Tokenizer son las siguientes.
<pad>, <eos>, <sep>, etc.) por defecto.tokenizer.vocab_size, lo cual es conveniente para establecer el vocab_size del modelo.Cargador de datos (DataLoader): Desempeña el papel de agrupar los conjuntos de datos generados por WikiSQLDataset en lotes miniatura y suministrarlos al modelo de manera eficiente. batch_size es el número de muestras que se ingresan al modelo a la vez, y shuffle=True mezcla los datos antes de cada época para mejorar el rendimiento del entrenamiento.
Configuración de MistralConfig: Establece los hiperparámetros relacionados con la estructura del modelo. En particular, configura pad_token_id, bos_token_id y eos_token_id a las ID de tokens correspondientes en tokenizer para que el modelo procese correctamente los tokens de padding, inicio de oración y fin de oración.
Creación del modelo (MistralForCausalLM) y optimizador (AdamW): Crea un modelo MistralForCausalLM y lo mueve al dispositivo especificado (CPU o GPU). Utiliza el optimizador AdamW y el programador de tasas de aprendizaje get_cosine_schedule_with_warmup para controlar la tasa de aprendizaje y optimizar el modelo.
Función train: Al igual que las funciones utilizadas en train_seq_num.py y train_math.py, utiliza un bucle de entrenamiento estándar para entrenar el modelo.
generate_sql): Inferencia de consultas SQL a partir de preguntasgenerate_sql: Utiliza el modelo entrenado para generar una consulta SQL a partir de una pregunta en lenguaje natural.
<sep> a la pregunta ingresada para formar un prompt en el formato "pregunta <sep> ". Este prompt informa claramente al modelo que la pregunta ha terminado y debe generar una consulta SQL.max_length) con un token <eos>. Sin embargo, si los datos de entrenamiento solo contienen "pregunta <sep>" sin la parte SQL ni el token <eos> (es decir, en el formato "pregunta <sep> <pad> <pad> ..."), el modelo no aprenderá qué generar después del token <sep>. Como resultado, durante la etapa de generación, el modelo podría generar solo tokens de padding después de <sep>, o incluso una cadena vacía. Para evitar esto, los datos de entrenamiento deben estar en el formato "pregunta <sep> SQL<eos>".temperature.<eos> o <pad>.train_sql.py es un ejemplo que muestra cómo utilizar el modelo simple_mistral para realizar la tarea de procesamiento de lenguaje natural más compleja de conversión de lenguaje natural a SQL. Este ejemplo enfatiza la importancia de utilizar adecuadamente tokens especiales (<sep>, <eos>, <pad>) en el proceso de preprocesamiento de datos, y cómo la composición de los datos de entrenamiento afecta las capacidades de generación del modelo.import torch
import random
from transformers import T5Tokenizer, get_cosine_schedule_with_warmup
from dldna.chapter_09.mistral.examples.train_sql import MistralConfig, MistralForCausalLM, WikiSQLDataset, generate_sql
from torch.utils.data import DataLoader
random.seed(42)
torch.manual_seed(42)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Use T5Tokenizer as the tokenizer (use T5's vocab_size and pad/eos tokens)
tokenizer = T5Tokenizer.from_pretrained("t5-small")
# WikiSQL dataset (training: train, evaluation: validation)
max_length = 128
train_dataset = WikiSQLDataset("train", tokenizer, max_length=max_length)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True, num_workers=2)
valid_dataset = WikiSQLDataset("validation", tokenizer, max_length=max_length)
valid_loader = DataLoader(valid_dataset, batch_size=1, shuffle=True)
# Model configuration: Use MistralConfig and MistralForCausalLM provided by simple_mistral.py
# The model size is adjusted for educational purposes.
config = MistralConfig(
vocab_size=tokenizer.vocab_size,
hidden_size=512,
intermediate_size=2048,
num_hidden_layers=4,
num_attention_heads=8,
num_key_value_heads=4, # num_attention_heads % num_key_value_heads == 0 must be true
max_position_embeddings=max_length,
sliding_window=max_length,
use_cache=False,
use_return_dict=True,
pad_token_id=tokenizer.pad_token_id, # Set the pad token id.
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id
)
model = MistralForCausalLM(config).to(device)
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-4)
num_epochs = 8 # Set the number of epochs small for the example
total_training_steps = num_epochs * len(train_loader)
scheduler = get_cosine_schedule_with_warmup(
optimizer,
num_warmup_steps=len(train_loader) // 5,
num_training_steps=total_training_steps
)
# Added code: Output WikiSQL data samples
print("=== WikiSQL Data Sample Output ===")
sample_count = 3 # Number of examples to output
for i in range(sample_count):
input_ids, labels = train_dataset[i]
decoded_text = tokenizer.decode(input_ids, skip_special_tokens=True)
print(f"Sample {i+1}: {decoded_text}")
print("Start training...")
train(model, train_loader, optimizer, scheduler, num_epochs, device)
# Save the model: Save the final model to a file.
torch.save(model.state_dict(), "final_nl2sql_model.pth")
# Evaluation code part
print("\n=== Evaluation Examples ===")
for i, (input_ids, labels) in enumerate(valid_loader):
if i >= 10:
break
# Keep special tokens with skip_special_tokens=False.
full_text = tokenizer.decode(input_ids[0], skip_special_tokens=False)
# Unify the tokens "sep>" and "eos>" to "<sep>" and "<eos>" respectively.
full_text = full_text.replace("sep>", "<sep>").replace("eos>", "<eos>")
if "<sep>" in full_text:
# Split based on the first <sep>, then join all subsequent parts to restore the complete SQL.
parts = full_text.split("<sep>")
question = parts[0].strip()
target_sql = "<sep>".join(parts[1:]).strip()
# If target_sql ends with "<eos>", remove it.
if target_sql.endswith("<eos>"):
target_sql = target_sql[:-len("<eos>")].strip()
else:
question = full_text.strip()
target_sql = ""
generated_sql = generate_sql(model, tokenizer, question, max_length, device, temperature=0.7)
# If there is a "sep>" token in generated_sql, extract the part after that token to use.
# if "sep>" in generated_sql:
# generated_sql = generated_sql.split("sep>", 1)[1].strip()
print(f"Question: {question}")
print(f"Target SQL: {target_sql}")
print(f"Generated SQL: {generated_sql}\n")You are using the default legacy behaviour of the <class 'transformers.models.t5.tokenization_t5.T5Tokenizer'>. This is expected, and simply means that the `legacy` (previous) behavior will be used so nothing changes for you. If you want to use the new behaviour, set `legacy=False`. This should only be set if you understand what it means, and thoroughly read the reason why this was added as explained in https://github.com/huggingface/transformers/pull/24565=== WikiSQL Data Sample Output ===
Sample 1: Tell me what the notes are for South Australia sep> SELECT Notes FROM table WHERE Current slogan = SOUTH AUSTRALIA eos>
Sample 2: What is the current series where the new series began in June 2011? sep> SELECT Current series FROM table WHERE Notes = New series began in June 2011 eos>
Sample 3: What is the format for South Australia? sep> SELECT Format FROM table WHERE State/territory = South Australia eos>
Start training...
Epoch 1/8, Average Loss: 10.5748, LR: 0.000000
Epoch 2/8, Average Loss: 9.7000, LR: 0.000001
Epoch 3/8, Average Loss: 7.2037, LR: 0.000001
Epoch 4/8, Average Loss: 5.5372, LR: 0.000001
Epoch 5/8, Average Loss: 4.5961, LR: 0.000001
Epoch 6/8, Average Loss: 4.0102, LR: 0.000002
Epoch 7/8, Average Loss: 3.6296, LR: 0.000002
Epoch 8/8, Average Loss: 3.3907, LR: 0.000002
=== Evaluation Examples ===
Question: Who was the minister for the CSV party with a present day end date? <unk>
Target SQL: SELECT Minister FROM table WHERE Party = csv AND End date = present day <unk> <eos></s><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad>
Generated SQL: Who was the minister for the CSV party with a present day end date? sep> FROM table WHERE60ed = s eos>
Question: What is the production number of From Hare to Heir? <unk>
Target SQL: SELECT SUM Production Number FROM table WHERE Title = from hare to heir <unk> <eos></s><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad>
Generated SQL: What is the production number of From Hare to Heir? sep>os FROM table WHERE Score = 0 eos>
Question: What was the score on January 12? <unk>
Target SQL: SELECT Score FROM table WHERE Date = january 12 <unk> <eos></s><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad>
Generated SQL: What was the score on January 12? sep>a Record FROM table WHERE # eos>
Question: The race tony bettenhausen 200 has what smallest rd? <unk>
Target SQL: SELECT MIN Rd FROM table WHERE Name = Tony Bettenhausen 200 <unk> <eos></s><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad>
Generated SQL: The race tony bettenhausen 200 has what smallest rd? sep> Team FROM table WHERE Player = a ODi a eos>
Question: what is the club that was founded before 2007, joined prsl in 2008 and the stadium is yldefonso solá morales stadium? <unk>
Target SQL: SELECT Club FROM table WHERE Founded <unk> 2007 AND Joined PRSL = 2008 AND Stadium = yldefonso solá morales stadium <unk> <eos></s><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad>
Generated SQL: what is the club that was founded before 2007, joined prsl in 2008 and the stadium is yldefonso solá morales stadium? sep> ( for for the highest FROM table WHERE Team = Rank of vir AND COUNT eos>
Question: Who is the co-contestant (yaar vs. Pyaar) with Vishal Singh as the main contestant? <unk>
Target SQL: SELECT Co-contestant (Yaar vs. Pyaar) FROM table WHERE Main contestant = vishal singh <unk> <eos></s><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad>
Generated SQL: Who is the co-contestant (yaar vs. Pyaar) with Vishal Singh as the main contestant? sep> SELECT Record FROM table WHERE ts = 9kt AND Date = a eos>
Question: What season did SV Darmstadt 98 end up at RL Süd (1st)? <unk>
Target SQL: SELECT Season FROM table WHERE RL Süd (1st) = SV Darmstadt 98 <unk> <eos></s><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad>
Generated SQL: What season did SV Darmstadt 98 end up at RL Süd (1st)? sep> FROM table WHERE Away team = s s eos>
Question: What character was portrayed by the same actor for 12 years on Neighbours? <unk>
Target SQL: SELECT Character FROM table WHERE Duration = 12 years AND Soap Opera = neighbours <unk> <eos></s><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad>
Generated SQL: What character was portrayed by the same actor for 12 years on Neighbours? sep>FS Class FROM table WHERE Date = m ja eos>
Question: What was the score between Marseille and Manchester United on the second leg of the Champions League Round of 16? <unk>
Target SQL: SELECT 2nd leg score** FROM table WHERE Opponent = Marseille <unk> <eos></s><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad>
Generated SQL: What was the score between Marseille and Manchester United on the second leg of the Champions League Round of 16? sep>hes> d FROM table WHERE Date =s eos>
Question: Who was the Man of the Match when the opponent was Milton Keynes Lightning and the venue was Away? <unk>
Target SQL: SELECT Man of the Match FROM table WHERE Opponent = milton keynes lightning AND Venue = away <unk> <eos></s><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad>
Generated SQL: Who was the Man of the Match when the opponent was Milton Keynes Lightning and the venue was Away? sep> with Cap? sep> SELECT Home team score FROM table WHERE Wilson AND jump = s eos>
Incluir arquitecturas eficientes como simple_mistral hace que construir modelos de transformers desde cero sea una tarea difícil pero gratificante. Aunque la comprensión teórica es importante, en el proceso de implementación real a menudo surgen errores sutiles y cuellos de botella de rendimiento. En esta sección, examinamos profundamente estrategias prácticas para diseñar, implementar y depurar transformers, centrándonos especialmente en los componentes utilizados en simple_mistral (RoPE, RMSNorm, Attention). Tratamos extensivamente las pruebas unitarias y discutimos otras técnicas de depuración y diseño esenciales.
Cuando se construyen modelos complejos como transformers, las pruebas unitarias no son una opción sino una necesidad. Ayudan a detectar errores temprano, prevenir regresiones y brindar confianza en la implementación. Un modelo bien probado es un modelo confiable.
Cada fuente de modelos tiene un directorio llamado tests con pruebas unitarias (por ejemplo: mistral/tests, phi3/tests)
Por qué las pruebas unitarias son importantes para los transformers
past_key_value): Cuando el modelo utiliza cachés como past_key_values, es importante verificar mediante pruebas unitarias que no haya errores relacionados con shape, dtype o device.Principios clave para pruebas unitarias efectivas
assert) para verificar que el código funcione como se espera. Escribe las assertions lo más específicas posible. No solo asegúrate de que el código se ejecute sin fallos, sino también de que la salida sea correcta.unittest, el marco pytest es el más recomendado en Python.Áreas de enfoque para pruebas unitarias de transformers * Forma de entrada/salida: El tipo más común de error en la implementación del transformer es un tensor con una forma incorrecta. Cada prueba debe incluir una afirmación para verificar la forma del tensor de salida. * Tipo de datos: Verifique que los tensores tengan el tipo de datos esperado (por ejemplo, torch.float32, torch.float16, torch.int64). * Colocación de dispositivos: Si está utilizando GPU, verifique que los tensores estén en el dispositivo correcto (CPU o GPU). * Estabilidad numérica: Asegúrese de que no haya NaN (Not a Number) ni Inf en los tensores después de operaciones como softmax o normalización. * Cálculo de gradientes: Verifique que los gradientes se calculen correctamente para todos los parámetros entrenables. * Caché (past_key_value): Como se mencionó anteriormente, el mecanismo de caché es una causa frecuente de errores. Pruebe exhaustivamente la decodificación incremental (incremental decoding).
Ejemplos detallados de pruebas unitarias (RoPE, RMSNorm, Attention)
# test_rope.py
import unittest
import torch
from dldna.chapter_09.mistral.simple_mistral import MistralRotaryEmbedding, apply_rotary_pos_emb, rotate_half
# ...# test_rms_norm.py
import torch
import pytest
from dldna.chapter_09.mistral.simple_mistral import PhiMiniRMSNorm
# ... # test_attention.py
import torch
import pytest
from dldna.chapter_09.mistral.simple_mistral import PhiMiniConfig, PhiMiniAttention
# ...
# Pruebas adicionales para la atención
def test_phi_mini_attention_zero_length_initial():
# ...
def test_phi_mini_attention_single_token_initial():
# ...
@pytest.mark.parametrize("batch_size", [1, 2, 4, 8])
def test_phi_mini_attention_various_batch_sizes(batch_size):
# ...
@pytest.mark.parametrize("num_heads, num_kv_heads", [(8, 8), (8, 4), (8, 1)]) # Casos MHA, GQA
def test_phi_mini_attention_different_head_configs(num_heads, num_kv_heads):
# ...
@pytest.mark.parametrize("dtype", [torch.float16, torch.bfloat16, torch.float32])
def test_phi_mini_attention_mixed_precision(dtype):
# ...
def test_phi_mini_attention_combined_mask():
# ...
def test_phi_mini_attention_long_sequence():
# ...
def test_phi_mini_attention_output_attentions_with_cache():
# ... Aunque las pruebas unitarias son fundamentales, no son la única herramienta en el conjunto de herramientas de depuración. Las siguientes son otras estrategias importantes.
1. Registro (Logging) * Registro estratégico: Agregar declaraciones de registro (sentencias print o, preferiblemente, el módulo logging) al código para rastrear los valores de las variables principales, la forma del tensor y el flujo de ejecución. Esto puede ayudar a identificar rápidamente dónde ocurre un problema. * Control de nivel de detalle: Hacer que el registro sea detallado pero proporcionar una manera de controlar el nivel de detalle (por ejemplo, usando banderas de línea de comandos o variables de entorno). Esto permite obtener información detallada durante la depuración pero evitar demasiada salida cuando se está funcionando normalmente.
2. Visualización (Visualization)
3. Depuración numérica (Numerical Debugging)
torch.isnan() y torch.isinf() para verificar si un tensor contiene valores NaN o Inf. Esto a menudo indica inestabilidad numérica. python if torch.isnan(tensor).any() or torch.isinf(tensor).any(): print("¡NaN o Inf detectados!")torch.autograd.gradcheck para verificar si una función autograd personalizada está calculando los gradientes correctamente. Esto es particularmente importante al implementar mecanismos de atención personalizados u otras tareas complejas.4. Depuradores (pdb, depuradores de IDE)
pdb (Python Debugger): Usar el depurador integrado de Python (pdb) para ejecutar el código línea por línea, examinar variables y establecer puntos de interrupción. python import pdb; pdb.set_trace() # Agregar esta línea para establecer un punto de interrupción.5. Perfilado (Profiling)
memory_profiler para rastrear el uso de memoria y detectar posibles fugas de memoria.6. Principios de diseño del modelo para facilitar la depuración * Manténgalo simple (Keep it Simple): Comience con un modelo simple y vaya aumentando gradualmente la complejidad. De esta manera, será más fácil aislar los errores. * Modularidad (Modularity): Divida el código en módulos pequeños y bien definidos. Esto facilita la prueba y depuración de componentes individuales. * Assertions: Use assertions para verificar las condiciones esperadas y detectar errores temprano. * Comentarios y documentación (Comments and Documentation): Escribe comentarios claros y concisos, así como documentación, para explicar la lógica del código. Esto ayuda a los usuarios (y a otras personas) a comprender el código e identificar posibles problemas. * Reproducibilidad (Reproducibility): Use una seed de random fija para que los resultados sean reproducibles. Esto es importante tanto para la depuración como para comparar diferentes configuraciones de modelos. * Sobreajuste a un solo lote/pequeño conjunto de datos (Overfitting): Ajuste el modelo a un pequeño conjunto de datos antes de entrenarlo con un conjunto de datos grande.
7. Errores comunes y formas de evitarlos
tensor.shape frecuentemente en el proceso de depuración.float32 vs float16).past_key_values: Asegúrese de seguir el método correcto para su uso.Combinar estas técnicas de depuración con un entendimiento sólido de los principios básicos de los modelos de transformers permitirá resolver incluso los problemas más difíciles de implementación. La depuración es un proceso iterativo, por lo que tenga paciencia y use todas las herramientas de manera sistemática.
Gemma es el más reciente modelo de código abierto publicado por Google en febrero de 2024. Aunque no introduce cambios revolucionarios en la estructura del modelo en comparación con Mistral, refleja las tendencias actuales de los modelos y tiene valor para ser estudiado debido a su utilidad en ciertos contextos. Gemma adopta una arquitectura de decodificador único (Decoder-only) basada en Transformer, similar a LLaMA y Mistral.
Reflejo de las tendencias actuales en modelos: Gemma incluye componentes comúnmente utilizados en los últimos modelos, como RoPE (Rotary Positional Embedding), RMSNorm (Root Mean Square Layer Normalization) y la función de activación GeGLU. Estos elementos contribuyen al rendimiento y a la eficiencia del modelo, y ayudan a comprender las tendencias actuales. RoPE codifica de manera eficiente información de posición relativa para mejorar la capacidad de procesar secuencias largas, mientras que RMSNorm aumenta la eficiencia computacional eliminando la operación de centrado en Layer Normalization. GeGLU es una variante de GLU (Gated Linear Unit) que aumenta la capacidad expresiva del modelo a través de la no linealidad.
Diversas tamaños de modelos: Gemma está disponible en tamaños de 2B, 7B, 9B y 27B. Esto permite a los usuarios con recursos computacionales limitados experimentar con un modelo relativamente pequeño (2B), mientras que los modelos más grandes (27B) ofrecen un rendimiento superior pero requieren mayores recursos computacionales. Los usuarios pueden elegir el tamaño de modelo adecuado según su entorno y necesidades.
Integración con el ecosistema de Google: Gemma está asociada al proyecto Gemini de Google y puede integrarse fácilmente con Google Cloud, Vertex AI, entre otros. Para los desarrolladores que utilizan principalmente la plataforma de Google, Gemma puede ser una opción útil. Vertex AI de Google Cloud proporciona una plataforma integral para el entrenamiento, despliegue y gestión de modelos de aprendizaje automático, y Gemma puede aumentar la productividad del desarrollo a través de su compatibilidad con estas plataformas.
Accesibilidad de los modelos de código abierto: Gemma se publica bajo la licencia Apache 2.0, permitiendo un uso, distribución y modificación libres, incluyendo el uso comercial. | Característica | Gemma | Mistral | |——————|———————————|———————————-| | Fecha de lanzamiento | Febrero de 2024 | Septiembre de 2023 | | Tamaño del modelo | 2B, 7B, 9B, 27B | 7.3B | | Arquitectura base | Transformer (solo Decoder) | Transformer (solo Decoder) | | Embedding de posición | RoPE | RoPE | | Normalización | RMSNorm | RMSNorm | | Función de activación | GeGLU | SwiGLU | | Atención | Multi-Head Attention (MHA), GQA| Grouped-Query Attention (GQA), SWA | | Ventana de contexto | Máximo 8192 tokens | Máximo 131,000 tokens | | Características principales| Diversos tamaños, soporte del ecosistema Google, GeGLU, amplia ventana de contexto | GQA y SWA para inferencia eficiente, procesamiento de contexto largo | | Innovación (comparativa)| Baja | Alta |
Gemma, aunque no es tan innovadora en su estructura de modelo como Mistral, tiene las siguientes importancias como un modelo de código abierto reciente:
En las secciones 9.6 y 9.7, examinamos los elementos clave de la arquitectura de modelos de lenguaje eficientes a través de los modelos Mistral y Gemma. En esta sección, implementaremos y analizaremos directamente el modelo Phi-3 Mini desarrollado por Microsoft, explorando el secreto detrás de su excelente rendimiento a pesar de su tamaño pequeño.
Phi-3 Mini es un modelo de lenguaje pequeño (SLM, Small Language Model) que Microsoft presentó en abril de 2024. Con 3.8B de parámetros, Phi-3 Mini muestra un rendimiento competitivo en varios benchmarks frente a modelos más grandes como Mistral (7B) y Gemma (7B), demostrando la posibilidad de modelos ligeros. En particular, Phi-3 Mini enfatiza la importancia de “datos de alta calidad” y “arquitectura eficiente”, señalando una nueva dirección más allá de la simple competencia en el tamaño del modelo. Esta filosofía se refleja bien en el eslogan “Textbooks Are All You Need”. simple_phi3.py es un código que implementa los componentes clave de Phi-3 Mini de manera simplificada. El código completo está en chapter_09/phi3.
simple_phi3 modelosimple_phi3 es un modelo implementado con fines educativos basado en Phi-3 Mini. En comparación con simple mistral del Capítulo 9.6, se tiene lo siguiente.
Resumen de diferencias funcionales del modelo
| Función | Simple Phi-3 | Simple Mistral |
|---|---|---|
| Atención | Multi-Head Attention (MHA) | Grouped-Query Attention (GQA) + Sliding Window Attention (SWA) |
| Activación | GELU (aproximación tanh) | SiLU |
| Normalización | RMSNorm | RMSNorm |
| Codificación posicional | RoPE | RoPE |
past_key_value |
Soportado (caching) | Soportado (caching) |
| Ventana deslizante | No soportado | Soportado |
| GQA | No soportado (usa MHA, K=V=Q, configuración de num_key_value_heads) |
Soportado |
| Atención de producto punto escalado | Uso de F.scaled_dot_product_attention |
Uso de F.scaled_dot_product_attention |
| Mejora del caching RoPE | Gestión eficiente de cachés cos, sin dentro del método forward, actualización con _set_cos_sin_cache cuando es necesario. Lógica optimizada para aplicar RoPE en el decoding incremental mediante la función apply_rotary_pos_emb_single, minimizando cálculos redundantes. |
Generación de cos_cached, sin_cached en el método _set_cos_sin_cache, uso en forward. Posibilidad de usar diferentes position IDs para queries y keys en apply_rotary_pos_emb. |
| Optimización de la máscara de atención | Uso de la función scaled_dot_product_attention, combinación eficiente de attention_mask y causal_mask, reducción de cálculos innecesarios |
Uso de la función scaled_dot_product_attention, manejo de attention_mask, sliding_window_mask |
return_dict |
Retorno flexible y claro de output mediante return_dict. |
Retorno de output a través de return_dict. |
| Vinculación de pesos | Enlace (tying) de los pesos de embedding y la capa de salida en post_init, reducción de parámetros y mejora del rendimiento |
No se menciona explícitamente el enlace de pesos |
Principales mejoras * Multi-Head Attention (MHA): En lugar de GQA (Grouped-Query Attention) de Mistral, utiliza MHA convencional. Phi-3 Mini demuestra que puede lograr un rendimiento adecuado sin GQA. * Mejora en el almacenamiento en caché de RoPE: Gestiona eficientemente las cachés cos y sin dentro del método forward, y actualiza solo cuando es necesario a través de _set_cos_sin_cache. Además, durante la decodificación incremental, optimiza la aplicación de RoPE utilizando la función apply_rotary_pos_emb_single para minimizar cálculos redundantes. * Optimización de Attention Mask: Combina eficientemente attention_mask y causal_mask al usar la función scaled_dot_product_attention para reducir cálculos innecesarios. * Weight Tying: En post_init, vincula (tied) los pesos de embebido con los pesos del layer de salida para reducir el número de parámetros y mejorar el rendimiento.
Ahora examinaremos en detalle los componentes clave del modelo simple_phi3.
La clase PhiMiniConfig define los hiperparámetros del modelo, siguiendo la configuración de Phi-3 Mini. Dado que ya se ha explicado con detalle en Mistral, lo omitiremos aquí.
La clase PhiMiniRMSNorm implementa RMSNorm (Root Mean Square Layer Normalization), similar a la versión de Mistral.
La clase PhiMiniRotaryEmbedding implementa RoPE (Rotary Positional Embedding). Aunque es similar a MistralRotaryEmbedding de Mistral, presenta las siguientes mejoras clave para maximizar la eficiencia del almacenamiento en caché.
forward:
forward, se utilizan directamente cos_cached y sin_cached. Es decir, si ya hay valores calculados, se utilizan inmediatamente.seq_len es mayor que max_seq_len_cached, lo que indica que se necesita una nueva longitud de secuencia en caché, se llama al método _set_cos_sin_cache para actualizar la caché. Esto evita la creación innecesaria de cachés y maximiza el reuso de valores ya calculados.max_seq_len_cached, cos_cached, sin_cached:
max_seq_len_cached: almacena la longitud máxima de secuencia en caché hasta ahora.cos_cached, sin_cached: almacenan los valores de coseno y seno precalculados.forward y se reutilizan para mejorar la eficiencia.apply_rotary_pos_emb_single: permite aplicar RoPE solo a los nuevos tokens en situaciones de decodificación incremental utilizando past_key_value. Como los resultados de RoPE para los tokens anteriores ya están almacenados en past_key_value, se evitan cálculos redundantes.Estas mejoras aumentan significativamente la eficiencia de las operaciones RoPE, proporcionando ventajas de rendimiento especialmente al procesar secuencias largas o generar texto.
La clase PhiMiniAttention implementa el mecanismo de atención de Phi-3 Mini. Aunque utiliza la atención multi-cabeza (MHA) convencional en lugar del GQA de Mistral, optimiza la aplicación de RoPE para mejorar la eficiencia.
past_key_value.
past_key_value (caso común): se generan IDs de posición para toda la secuencia (0 a q_len - 1).past_key_value (decodificación incremental): se generan IDs de posición para el nuevo token (past_len a past_len + q_len - 1) y para toda la secuencia clave (0 a past_len + q_len - 1).apply_rotary_pos_emb_single, cuando hay past_key_value (decodificación incremental), se aplica RoPE solo al nuevo token(query).past_key_value para almacenar en caché los tensores de clave/valor de pasos anteriores y mejorar la velocidad de inferencia.rotate_half, apply_rotary_pos_emb, apply_rotary_pos_emb_singlerotate_half: Es una función auxiliar necesaria para implementar RoPE, similar a Mistral.apply_rotary_pos_emb: Aplica RoPE a los tensores de consulta(q) y clave(k). A diferencia de Mistral, solo recibe un conjunto de position_ids (aplicado igualmente a la consulta y la clave).apply_rotary_pos_emb_single: En situaciones de decodificación incremental con past_key_value, aplica RoPE al tensor de entrada x (consulta o clave).La clase PhiMiniMLP implementa una red FeedForward, similar a Mistral, utilizando la función de activación GELU.
La clase PhiMiniDecoderLayer utiliza la estructura Pre-Norm y las conexiones residuales, al igual que Mistral.
La clase PhiMiniModel compone el modelo Phi-3 Mini completo, similar a Mistral.
La clase PhiMiniForCausalLM agrega una cabeza (lm_head) para modelado de lenguaje al PhiMiniModel.
post_init:
self.transformer.embed_tokens.weight) con los pesos del último nivel (self.lm_head.weight). Esto reduce el número de parámetros, evita el sobreajuste y generalmente mejora el rendimiento.generate: Función para generar texto, que resuelve problemas relacionados con RoPE durante la decodificación incremental al pasar solo el último token en lugar de toda la secuencia a forward() cuando existen past_key_values.simple_phi3: cálculo de expresiones complejasComo ejemplo práctico del modelo simple_phi3 revisado en la sección 9.8.1, probaremos su capacidad para calcular expresiones matemáticas complejas. A través de este ejemplo, evaluaremos si modelos de lenguaje pequeños (SLM) como el Phi-3 Mini pueden manejar no solo operaciones básicas de suma y resta, sino también multiplicación y expresiones más complejas con paréntesis, analizando su rendimiento y limitaciones.
La ubicación del código de ejemplo es chapter_09/phi3/examples/train_math.py.
Significado del ejemplo
Forma de los datos de entrenamiento
Usando la función create_complex_arithmetic_data, generamos datos de expresiones matemáticas complejas con las siguientes características:
expresión=resultado<eos> (ej: (12+7)*3=57<eos>, 12+7*3=33<eos>)Resultados del entrenamiento
Muestra 1: 41*8-2=326<eos>
Muestra 2: 15+(9*48)=447<eos>
Muestra 3: 35-6+38=67<eos>
Muestra 4: 6*14*15=1260<eos>
Muestra 5: 36*(13*46)=21528<eos>
...(omisión del registro de entrenamiento)...
Prompt: '23-23-50=' --> Resultado generado: '23-23-50=-50' (Respuesta correcta: 23-23-50=-50<eos>)
Prompt: '39-46-15=' --> Resultado generado: '39-46-15=-22' (Respuesta correcta: 39-46-15=-22<eos>)
Prompt: '(33-30)+30=' --> Resultado generado: '(33-30)+30=33' (Respuesta correcta: (33-30)+30=33<eos>)
Prompt: '6*14*15=' --> Resultado generado: '6*14*15=1260' (Respuesta correcta: 6*14*15=1260<eos>)Análisis
simple_phi3 generó respuestas que coinciden con las correctas o son muy similares. Esto indica que el modelo ha aprendido bien las reglas operacionales para expresiones matemáticas complejas.Conclusión
A pesar de tener solo alrededor de 120,000 parámetros, el modelo simple_phi3 logró un alto nivel de precisión (aproximadamente 80%) en el cálculo de expresiones matemáticas complejas. Esto sugiere que ha aprendido reglas complejas como el manejo de paréntesis y el orden de las operaciones. En comparación con modelos de lenguaje grandes (LLM) que tienen miles de millones de parámetros, simple_phi3 demuestra un rendimiento impresionante a pesar de su tamaño extremadamente pequeño (0.12M).
import torch
import random
from dldna.chapter_09.phi3.examples.train_complex_math import PhiMiniConfig, PhiMiniForCausalLM, ComplexArithmeticDataset, train, create_complex_arithmetic_data, create_tokenizer, create_reverse_tokenizer, generate_text
from torch.utils.data import DataLoader
random.seed(42)
torch.manual_seed(42)
device = "cuda" if torch.cuda.is_available() else "cpu"
# Hyperparameters
num_samples = 100000 # Sufficiently large amount of data
max_value = 50 # Maximum value of operands (for slightly complex calculations)
seq_length = 30 # Complex arithmetic problems can have somewhat long expressions
batch_size = 128
epochs = 30
learning_rate = 1e-3
# Data generation
complex_data = create_complex_arithmetic_data(num_samples, max_value)
print("Training data examples:")
for i in range(5):
print(f"Sample {i+1}: {complex_data[i]}")
# Create tokenizer and reverse tokenizer
tokenizer = create_tokenizer()
reverse_tokenizer = create_reverse_tokenizer(tokenizer)
updated_vocab_size = len(tokenizer)
# Configure Dataset and DataLoader
dataset = ComplexArithmeticDataset(complex_data, seq_length, tokenizer)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# PhiMini Model Configuration
config = PhiMiniConfig(
vocab_size=updated_vocab_size,
hidden_size=64, # Small model size for experimentation
intermediate_size=128,
num_hidden_layers=3,
num_attention_heads=8,
num_key_value_heads=8, # K=V=Q
max_position_embeddings=128,
use_cache=False,
use_return_dict=True,
)
config.pad_token_id = tokenizer["<pad>"]
config.eos_token_id = tokenizer["<eos>"]
# Create PhiMini For CausalLM Model
model = PhiMiniForCausalLM(config).to(device)
print("Total Trainable Parameters:", sum(p.numel() for p in model.parameters() if p.requires_grad))
# weight tying (share weights between embedding and lm_head)
model.lm_head.weight = model.transformer.embed_tokens.weight
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=epochs, eta_min=1e-5)
# Model Training
print("Start training...")
train(model, dataloader, optimizer, scheduler, epochs, device)
# Save Model
save_path = "phimini_complex_math.pt"
torch.save(model.state_dict(), save_path)
print(f"Model saved: {save_path}")
# Load Saved Model (create a new model object before testing and load_state_dict)
loaded_model = PhiMiniForCausalLM(config).to(device)
loaded_model.load_state_dict(torch.load(save_path, map_location=device))
loaded_model.eval()
# Generate and Print Results with Test Set, Calculate Accuracy
print("\nTest sample generation results:")
test_samples = random.sample(complex_data, 10)
correct_count = 0
for sample in test_samples:
prompt = sample.split('=')[0] + '='
generated = generate_text(loaded_model, prompt, tokenizer, reverse_tokenizer, seq_length, device, temperature=0.1) # Reduce temperature for testing
answer = sample.split('=')[1].replace('<eos>', '')
if generated.split('=')[1] == answer:
correct_count += 1
print(f"Prompt: '{prompt}' --> Generated result: '{generated}' (Correct answer: {sample})")
accuracy = (correct_count / len(test_samples)) * 100
print(f"\nOverall accuracy: {accuracy:.2f}% ({correct_count}/{len(test_samples)})")Training data examples:
Sample 1: 41*8-2=326<eos>
Sample 2: 15+(9*48)=447<eos>
Sample 3: 35-6+38=67<eos>
Sample 4: 6*14*15=1260<eos>
Sample 5: 36*(13*46)=21528<eos>
Total Trainable Parameters: 126208
Start training...
Epoch 1/30, Avg Loss: 0.7439, LR: 0.000997
Epoch 2/30, Avg Loss: 0.6393, LR: 0.000989
Epoch 3/30, Avg Loss: 0.6139, LR: 0.000976
Epoch 4/30, Avg Loss: 0.5919, LR: 0.000957
Epoch 5/30, Avg Loss: 0.5825, LR: 0.000934
Epoch 6/30, Avg Loss: 0.5753, LR: 0.000905
Epoch 7/30, Avg Loss: 0.5696, LR: 0.000873
Epoch 8/30, Avg Loss: 0.5649, LR: 0.000836
Epoch 9/30, Avg Loss: 0.5599, LR: 0.000796
Epoch 10/30, Avg Loss: 0.5558, LR: 0.000753
Epoch 11/30, Avg Loss: 0.5522, LR: 0.000706
Epoch 12/30, Avg Loss: 0.5479, LR: 0.000658
Epoch 13/30, Avg Loss: 0.5443, LR: 0.000608
Epoch 14/30, Avg Loss: 0.5409, LR: 0.000557
Epoch 15/30, Avg Loss: 0.5370, LR: 0.000505
Epoch 16/30, Avg Loss: 0.5339, LR: 0.000453
Epoch 17/30, Avg Loss: 0.5307, LR: 0.000402
Epoch 18/30, Avg Loss: 0.5280, LR: 0.000352
Epoch 19/30, Avg Loss: 0.5242, LR: 0.000304
Epoch 20/30, Avg Loss: 0.5217, LR: 0.000258
Epoch 21/30, Avg Loss: 0.5189, LR: 0.000214
Epoch 22/30, Avg Loss: 0.5161, LR: 0.000174
Epoch 23/30, Avg Loss: 0.5137, LR: 0.000137
Epoch 24/30, Avg Loss: 0.5120, LR: 0.000105
Epoch 25/30, Avg Loss: 0.5101, LR: 0.000076
Epoch 26/30, Avg Loss: 0.5085, LR: 0.000053
Epoch 27/30, Avg Loss: 0.5073, LR: 0.000034
Epoch 28/30, Avg Loss: 0.5062, LR: 0.000021
Epoch 29/30, Avg Loss: 0.5055, LR: 0.000013
Epoch 30/30, Avg Loss: 0.5050, LR: 0.000010
Model saved: phimini_complex_math.pt
Test sample generation results:
Prompt: '23-23-50=' --> Generated result: '23-23-50=-50' (Correct answer: 23-23-50=-50<eos>)
Prompt: '39-46-15=' --> Generated result: '39-46-15=-22' (Correct answer: 39-46-15=-22<eos>)
Prompt: '(33-30)+30=' --> Generated result: '(33-30)+30=33' (Correct answer: (33-30)+30=33<eos>)
Prompt: '30+14*27=' --> Generated result: '30+14*27=408' (Correct answer: 30+14*27=408<eos>)
Prompt: '(13-22)-18=' --> Generated result: '(13-22)-18=-27' (Correct answer: (13-22)-18=-27<eos>)
Prompt: '9-15+12=' --> Generated result: '9-15+12=6' (Correct answer: 9-15+12=6<eos>)
Prompt: '28*(3+31)=' --> Generated result: '28*(3+31)=960' (Correct answer: 28*(3+31)=952<eos>)
Prompt: '24*(12+1)=' --> Generated result: '24*(12+1)=320' (Correct answer: 24*(12+1)=312<eos>)
Prompt: '(1-33)+26=' --> Generated result: '(1-33)+26=-6' (Correct answer: (1-33)+26=-6<eos>)
Prompt: '24+47+6=' --> Generated result: '24+47+6=77' (Correct answer: 24+47+6=77<eos>)
Overall accuracy: 80.00% (8/10)En el Capítulo 9, hemos seguido la evolución de los Transformers desde su presentación en 2017 con el paper pionero “Attention is All You Need” hasta la actualidad en 2025, centrándonos en las dos fuerzas impulsoras clave del desarrollo de los Transformers: eficiencia y escalabilidad.
Los primeros Transformers mostraron un rendimiento revolucionario, pero se enfrentaron a una limitación fundamental: el aumento exponencial del cálculo y el uso de memoria con la longitud de las secuencias. El Capítulo 9 aborda en profundidad los esfuerzos constantes para superar estas restricciones, incluyendo enfoques puramente software (Sección 9.2), combinaciones de hardware y software (Sección 9.3) y diversas innovaciones técnicas para mejorar la escalabilidad del modelo (Sección 9.4). Desde los ejemplos de implementación de RoPE y FlashAttention (Sección 9.5) hasta el análisis de las arquitecturas de modelos recientes como Mistral, Gemma y Phi-3 Mini (Secciones 9.6, 9.7, 9.8), exploramos exhaustivamente tanto la teoría como la implementación práctica para iluminar las arquitecturas Transformers más eficientes.
Gracias a estos avances tecnológicos, los Transformers se han convertido en una herramienta poderosa capaz de comprender contextos más largos, resolver problemas más complejos y aplicarse a un rango más amplio de campos. Es evidente el papel crucial que han jugado la eficiencia y escalabilidad en el crecimiento de los Transformers desde simples modelos de lenguaje hasta convertirse en un motor central para el desarrollo de tecnologías de inteligencia artificial.
Por supuesto, aún quedan desafíos por resolver. El aumento del consumo energético asociado al agrandamiento de los modelos, problemas de sesgo y daño, y la cuestión de la interpretabilidad de los modelos son desafíos importantes que debemos superar en el futuro. La investigación para desarrollar sistemas de IA más seguros, confiables y capaces de colaborar armónicamente con humanos continuará.
A partir del Capítulo 10 y 11, iniciaremos un viaje hacia el mundo multimodal de los Transformers, que va más allá del dominio único del texto para integrar diversas tipos de datos como imágenes, audio y video. Los modelos multimodales que combinan información de múltiples modalidades ofrecen representaciones más ricas y potentes, lo que permite inferencias más complejas. Exploraremos los mecanismos de atención multimodal y sus infinitas posibilidades de aplicación a través de pioneros modelos como ViT, CLIP, DALL-E, Stable Diffusion, Flamingo, GATO y Gemini. Las innovaciones en eficiencia y escalabilidad discutidas en el Capítulo 9 sentarán las bases sólidas para el futuro de los Transformers multimodales que se presentará en los Capítulos 10 y 11.
En el desarrollo de los modelos de lenguaje a gran escala (LLM), Mixture of Experts (MoE) ha surgido como un marco que resuelve innovadoramente el equilibrio entre la capacidad del modelo y la eficiencia computacional. MoE funciona combinando varias redes “expertas” y activando selectivamente las expertas apropiadas para cada entrada a través de una red de puerta. Aquí se desglosan en profundidad los mecanismos clave de MoE, y se organiza sistemáticamente la teoría extendida basada en las tendencias de investigación más recientes.
Redes expertas: Existen N redes expertas \(\{E_i\}_{i=1}^N\), generalmente compuestas por Redes Neuronales Feedforward (FFN). Cada experta recibe una entrada \(x\) y genera una salida \(E_i(x)\).
Red de puerta: La red de puerta \(G\) toma la entrada \(x\) y produce pesos (probabilidades) para cada experta. Estos pesos indican qué experta es la más adecuada para la entrada \(x\). La salida de la red de puerta \(G(x)\) es un vector de N dimensiones, donde cada elemento \(G(x)_i\) representa el peso para la i-ésima experta.
Salida final: La salida final del modelo MoE \(y\) se calcula como una suma ponderada de las salidas de las expertas.
\(y = \sum_{i=1}^{N} G(x)_i E_i(x)\)
Al reinterpretar el sistema MoE como un modelo gráfico probabilístico, la distribución conjunta de los datos observados \(\mathbf{x}\) y las variables latentes \(\mathbf{z}\) (indicadoras de selección de experta) se modela como sigue:
\(p(\mathbf{x}, \mathbf{z}|\theta) = p(\mathbf{z}|\theta_g)p(\mathbf{x}|\mathbf{z},\theta_e)\)
donde \(\theta_g\) son los parámetros de la red de puerta y \(\theta_e\) son los parámetros de las redes expertas. En el marco de inferencia variacional, la Cota Inferior del Evidencia (ELBO) se deriva como:
\(\mathcal{L}(\theta, \phi) = \mathbb{E}_{q_\phi(\mathbf{z}|\mathbf{x})}[\log p_\theta(\mathbf{x}|\mathbf{z})] - D_{KL}(q_\phi(\mathbf{z}|\mathbf{x}) \parallel p(\mathbf{z}))\)
Este enfoque redefine el proceso de aprendizaje de MoE dentro de un sistema de inferencia bayesiana, proporcionando una base teórica para la división del conocimiento entre las expertas. En particular, la técnica de reparametrización Gumbel-Softmax aproxima continuamente el proceso discreto de selección de experta, permitiendo la aplicación del descenso por gradiente.
\(\mathbf{z} = \text{softmax}((\log \boldsymbol{\pi} + \mathbf{g})/\tau)\)
donde \(\mathbf{g}\) es ruido Gumbel y \(\tau\) es un parámetro de temperatura.
Multi-Head Latent Attention (MLA) introducido en DeepSeek-V2 reduce significativamente la caché Key-Value [5, 6]. Esto se implementa a través de un enfoque que bifurca la jerarquía de expertos en partición espacial (Spatial Partitioning) y partición funcional (Functional Partitioning).
\(E_i(\mathbf{x}) = \sum_{h=1}^H W_{h,i}^o \cdot \text{GeLU}(W_{h,i}^k \mathbf{x} \oplus W_{h,i}^v \mathbf{x})\)
Dentro de cada experto, las cabezas de atención actúan como subexpertos independientes y maximizan la eficiencia paramétrica a través de matrices base compartidas (shared basis matrices).
El modelo Mixtral 8x7B introdujo un mecanismo para reconstruir dinámicamente la estructura de conexión de los expertos en función de los datos de entrada. La red de enrutamiento ha evolucionado más allá de una simple selección de expertos, convirtiéndose en una red neuronal gráfica (Graph Neural Network) que ajusta la intensidad de las conexiones entre expertos.
\(A_{ij}^{(l)} = \sigma(f_\phi(\mathbf{h}_i^{(l)}, \mathbf{h}_j^{(l)}))\)
Aquí, \(A_{ij}\) representa el peso de conexión entre los expertos \(i\) y \(j\), lo que permite la extracción de características multi-escala a través del mecanismo de atención jerárquica.
Optimización Equilibrada (Balanced Optimization): Para abordar el problema del desequilibrio de carga entre los expertos, se introdujo la técnica de descomposición dual (Dual Decomposition), utilizando el método de multiplicadores de Lagrange para restringir explícitamente la desviación estándar de la utilización de los expertos.
\(\mathcal{L}_{\text{total}} = \mathcal{L}_{\text{task}} + \lambda \sum_{i=1}^N (\mathbb{E}[u_i] - \bar{u})^2\)
Aquí, \(u_i\) es la utilización del experto \(i\), y \(\bar{u}\) es la tasa de utilización promedio objetivo.
Distilación de Conocimiento en Múltiples Capas: Se propuso una distilación de conocimiento jerárquica (Hierarchical Knowledge Distillation) que refleja la estructura jerárquica de los modelos MoE. \(\mathcal{L}_{KD} = \sum_{l=1}^{L}\alpha_{l}D_{KL}(g^{\text{teacher}}_{l} || g^{\text{student}}_{l})\) Al minimizar individualmente la divergencia KL de las distribuciones de puerta \(g_{l}\) en cada capa MoE, se posibilita la transferencia de conocimientos especializados de los expertos.
La GPU NVIDIA H100 Tensor Core introduce una Unidad de Ejecución Dispersa (Sparse Execution Unit) dedicada a MoE, que acelera las operaciones de routing Top-k. * Control dinámico de warp: Gestión independiente del flujo de ejecución por grupo de expertos * Memoria compartida jerárquica: Optimización del intercambio de resultados intermedios entre expertos * Paralelismo de modelo asincrónico: Minimización de latencia durante la ejecución distribuida de expertos
Investigaciones recientes han desarrollado técnicas para reducir el ancho de banda de comunicación al cuantizar los parámetros del experto a 4 bits[5]. Se aplica la técnica de cuantización diferencial (Differential Quantization). \(\Delta W_{i} = \text{sign}(W_{i}-\hat{W})\cdot 2^{\lfloor \log_{2}|W_{i}-\hat{W}|\rfloor}\) Aquí, \(\hat{W}\) representa la matriz base compartida, y solo se cuantizan las desviaciones por experto para minimizar la pérdida de precisión.
La investigación más reciente de Google DeepMind en 2025 propuso CES-MoE, que modela los expertos como una distribución en un espacio continuo en lugar de objetos discretos. Utiliza un modelo de difusión de expertos basado en movimiento browniano.
\(dE_t = \mu(E_t,t)dt + \sigma(t)dW_t\)
Este enfoque modela la evolución gradual de las características del experto y muestra un rendimiento excelente en adaptación dinámica de dominio (Dynamic Domain Adaptation).
En las arquitecturas MoE de próxima generación, se están realizando investigaciones para reemplazar las redes de expertos con ecuaciones diferenciales neuronales (Neural ODEs)
\(\frac{d\mathbf{h}(t)}{dt} = f_\theta(\mathbf{h}(t), t)\)
Esto permite modelar las características evolutivas temporales de los expertos y ha logrado una mejora en el rendimiento en tareas de inferencia a largo plazo (Long-horizon Inference).
El sistema HyperClova X-MoE de Naver distribuyó 1,024 expertos mediante clústerización jerárquica.
GPT-4o de OpenAI aplicó MoE al aprendizaje multimodal.
\(\mathbf{h}_{\text{fused}} = \sum_{i=1}^N G(\mathbf{x}_{\text{text}} \oplus \mathbf{x}_{\text{image}})_i E_i(\mathbf{x}_{\text{text}}, \mathbf{x}_{\text{image}})\)
Operaron expertos en un espacio de incrustación conjunto texto-imagen, mejorando el rendimiento de la inferencia cruzada modal.
Referencias:
[1] Fedus, W., Zoph, B., & Shazeer, N. (2021). Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity. arXiv preprint arXiv:2101.03961.
[2] Shazeer, N., Mirhoseini, A., Maziarz, K., Davis, A., Le, Q., Hinton, G., & Dean, J. (2017). Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. arXiv preprint arXiv:1701.06538.
[3] Jacobs, R. A., Jordan, M. I., Nowlan, S. J., & Hinton, G. E. (1991). Adaptive mixtures of local experts. Neural computation, 3(1), 79-87.
[4] NVIDIA Developer Blog. (2024). Applying Mixture of Experts in LLM Architectures. https://developer.nvidia.com/blog/applying-mixture-of-experts-in-llm-architectures/
[5] Materiales relacionados con DeepSeek-V2: * Modu Labs Blog. https://modulabs.co.kr/blog/deepseek-r1-introduction * HyperLab. https://hyperlab.hits.ai/blog/ai-deepseek * Wikidocs. https://wikidocs.net/275230 [6] Chung, E. (2023). Arquitectura de próxima generación después del Transformer de tendencias - MoE, SSM, RetNet, V-JEPA. Velog. https://velog.io/@euisuk-chung/%ED%8A%B8%EB%A0%8C%EB%93%9C-%ED%8A%B8%EB%A0%8C%EC%8A%A4%ED%8F%AC%EB%A8%B8-%EC%9D%B4%ED%9B%84%EC%9D%98-%EC%B0%A8%EC%84%B8%EB%8C%80-%EC%95%84%ED%82%A4%ED%85%8D%EC%B3%90-MoE-SSM-RetNet-V-JEPA
[7] The Moonlight. (2024). GG MoE vs MLP en Datos Tabulares. https://www.themoonlight.io/ko/review/gg-moe-vs-mlp-on-tabular-data
[8] Unite.AI. (2024). Modelo MoE 8x7B de la Última Versión de Mistral AI. https://www.unite.ai/ko/mistral-ais-latest-mixture-of-experts-moe-8x7b-model/
[9] Turing Post (2024) Benchmark MS EUREKA. [https://turingpost.co.kr/p/ms-eureka-benchmark](https://turingpost.co
Problemas básicos
Problemas de aplicación
Problemas avanzados
Complejidad computacional del mecanismo de atención: El mecanismo de atención calcula la relación entre cada par de tokens. Cuando la longitud de la secuencia es n, para cada uno de los n tokens se deben calcular las relaciones con los otros (n-1) tokens, por lo que se necesitan aproximadamente n * (n-1) ≈ n² operaciones. Por lo tanto, la complejidad computacional es O(n²).
Optimización FlashAttention: FlashAttention aprovecha al máximo el SRAM (memoria rápida) de la GPU. Divide las entradas en pequeños bloques, los carga en el SRAM y realiza cálculos de atención a nivel de bloque, luego escribe los resultados de nuevo en el HBM (memoria lenta). De esta manera, se reduce el número de accesos al HBM, minimizando la I/O de memoria y aumentando la velocidad de cálculo.
MQA vs. GQA:
PagedAttention & vLLM: PagedAttention adopta el concepto de paginación del sistema operativo para almacenar el caché KV en bloques de memoria no contiguos (páginas). vLLM utiliza PagedAttention para reducir el desperdicio de memoria, gestionando dinámicamente el caché KV y mejorando la velocidad de inferencia y el rendimiento.
Hierarchical Attention vs. Recurrent Memory Transformer:
Escribir código para clasificación de texto: (Se omite la escritura del código) Basándose en el ejemplo del Capítulo 9.5, utiliza la función efficient_encoder en lugar de nn.TransformerEncoderLayer, y aplica FlashAttention, Pre-LN, Gradient Checkpointing. Agrega código para cargar y preprocesar el conjunto de datos, entrenar y evaluar el modelo.
Conversión número-palabra: (Se omite la escritura del código) Carga un modelo Simple Mistral y prepara los datos de entrenamiento como pares de números y sus representaciones en palabras. Entrena el modelo y evalúa su rendimiento con datos de prueba. (Ejemplo: puntuación BLEU)
Conversión lenguaje natural-SQL: (Se omite la escritura del código) Carga un modelo Simple Mistral y prepara los datos de entrenamiento como pares de preguntas en lenguaje natural y consultas SQL. Entrena el modelo y evalúa su rendimiento con datos de prueba. (Ejemplo: precisión, viabilidad)
Propuesta de Constitutional AI: (Se omite la implementación) Constitutional AI define una serie de reglas (constitución) para las respuestas del modelo y evalúa y modifica las respuestas según estas reglas. Para aplicar esto a un modelo transformer, se pueden: (1) definir reglas éticas/seguras, (2) agregar un módulo separado para evaluar la salida del modelo, o (3) utilizar una función de pérdida que refleje las reglas durante el proceso de fine-tuning.
Análisis matemático de FlashAttention: (se omite el análisis matemático) FlashAttention reduce la cantidad de accesos a HBM mediante operaciones en bloques. Mientras que la atención tradicional requiere acceso a memoria O(n²), FlashAttention solo necesita acceso a HBM O(n²/B), donde B es el tamaño del bloque (limitado por el tamaño de SRAM de GPU).
Métodos para reducir el tamaño del caché KV:
Nuevos mecanismos de atención propuestos: (sugerencias de ideas)
Limitaciones y soluciones para el Constitutional AI:
Note: The last item (LongLoRA) seems to be a duplicate of the fourth item in the list, which also links to https://arxiv.org/abs/2311.02394. If this is not intended, please clarify or provide the correct reference. 1. Attention Is All You Need (Paper Original del Transformer): Paper que propuso la estructura básica del modelo de transformador y el mecanismo de atención. https://arxiv.org/abs/1706.03762 2. FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness: Paper que propone FlashAttention, que optimiza el cálculo de atención utilizando la jerarquía de memoria de GPU. https://arxiv.org/abs/2205.14135 3. FlashAttention-v2: Faster Attention with Better Parallelism and Work Partitioning: Versión mejorada de FlashAttention que ofrece mayor velocidad y procesamiento paralelo mejorado. https://arxiv.org/abs/2307.08691 4. Scaling Transformer to 1M tokens and beyond with RMT: Propone cómo escalar la longitud de contexto del modelo de transformador a más de 1M de tokens utilizando Recurrent Memory Transformer (RMT). https://arxiv.org/abs/2304.11062 5. Constitutional AI: Harmlessness from AI Feedback: Propone el marco de Constitutional AI para controlar las respuestas del modelo de IA según principios éticos. https://arxiv.org/abs/2212.08073 6. vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention: Introduce la biblioteca vLLM que mejora la velocidad de inferencia y el rendimiento del procesamiento de modelos de lenguaje a gran escala utilizando PagedAttention. https://arxiv.org/abs/2309.06180, https://vllm.ai/ 7. GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints: Introduce la técnica GQA para entrenar eficientemente modelos de atención multi-query a partir de puntos de control de atención multi-cabeza. https://arxiv.org/abs/2305.13245 8. LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models: Propone el método LongLoRA para afinar eficientemente modelos de lenguaje a gran escala con contexto largo. https://arxiv.org/abs/2311.02394 9. Mistral-7B: Descripción del modelo de lenguaje de alto rendimiento Mistral-7B, que cuenta con 7 mil millones de parámetros. https://arxiv.org/abs/2310.06825 10. The Illustrated Transformer: Material de blog que explica fácilmente el funcionamiento del modelo Transformer con ilustraciones. http://jalammar.github.io/illustrated-transformer/ 11. Hugging Face Transformers Documentation: Documentación oficial de la biblioteca Hugging Face Transformers, que ayuda a usar y aprender modelos Transformer de manera sencilla. https://huggingface.co/transformers/ 12. PyTorch Documentation: Documentación oficial del marco de deep learning PyTorch, que proporciona funciones necesarias para la implementación y aprendizaje de modelos Transformer. https://pytorch.org/docs/stable/index.html 13. TensorFlow Documentation: Documentación oficial del marco de deep learning TensorFlow, que proporciona API para la implementación y aprendizaje de modelos Transformer. https://www.tensorflow.org/api_docs 14. The Annotated Transformer: Material del grupo Harvard NLP que explica en detalle el artículo “Attention is all you need” con código PyTorch. http://nlp.seas.harvard.edu/2018/04/03/attention.html 15. DeepMind’s Blog on AlphaFold: Artículo de blog de DeepMind sobre el modelo de predicción de estructura proteica AlphaFold, que es un caso de uso basado en Transformer. https://www.deepmind.com/blog/alphafold-a-solution-to-a-50-year-old-grand-challenge-in-biology